TECHNICAL ASSET FINGERPRINT
70f05aaea61090dac530e04b
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
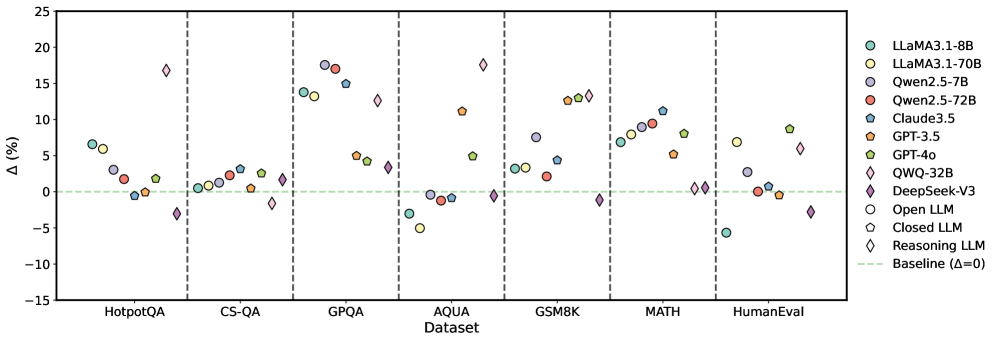
## Scatter Plot: Performance Comparison of Large Language Models
### Overview
This scatter plot compares the performance of several Large Language Models (LLMs) across seven different datasets. The y-axis represents the percentage difference in performance (Δ (%)) relative to a baseline, and the x-axis represents the dataset name. Each LLM is represented by a unique marker and color. A horizontal dashed line at Δ=0 indicates the baseline performance level.
### Components/Axes
* **X-axis:** Dataset - with markers for HotpotQA, CS-QA, GPQA, AQUA, GSM8K, MATH, and HumanEval.
* **Y-axis:** Δ (%) - Percentage difference in performance, ranging from approximately -15% to 25%.
* **Legend (Top-Right):**
* Llama3.1-8B (Green)
* Llama3.1-70B (Light Green)
* Qwen2.5-7B (Orange)
* Qwen2.5-72B (Red)
* Claude3.5 (Blue)
* GPT-3.5 (Dark Orange)
* GPT-4o (Yellow)
* QWQ-32B (Purple)
* DeepSeek-v3 (Pink)
* Open LLM (Grey)
* Closed LLM (Light Grey)
* Reasoning LLM (Diamond - Light Blue)
* Baseline (Δ=0) (Horizontal dashed line)
### Detailed Analysis
The plot shows the performance variation of each LLM across the datasets. I will analyze each dataset individually, noting trends and approximate values.
* **HotpotQA:**
* Llama3.1-8B: Approximately +3% to +8%
* Llama3.1-70B: Approximately +5% to +10%
* Qwen2.5-7B: Approximately +2% to +7%
* Qwen2.5-72B: Approximately +3% to +8%
* Claude3.5: Approximately +1% to +5%
* GPT-3.5: Approximately +2% to +6%
* GPT-4o: Approximately +5% to +10%
* QWQ-32B: Approximately +1% to +5%
* DeepSeek-v3: Approximately -2% to +3%
* Open LLM: Approximately -1% to +3%
* Closed LLM: Approximately -3% to +1%
* Reasoning LLM: Approximately -5% to +2%
* **CS-QA:**
* Llama3.1-8B: Approximately -2% to +3%
* Llama3.1-70B: Approximately +1% to +6%
* Qwen2.5-7B: Approximately -1% to +4%
* Qwen2.5-72B: Approximately +2% to +7%
* Claude3.5: Approximately -1% to +4%
* GPT-3.5: Approximately -1% to +4%
* GPT-4o: Approximately +3% to +8%
* QWQ-32B: Approximately +1% to +6%
* DeepSeek-v3: Approximately -3% to +2%
* Open LLM: Approximately -4% to +1%
* Closed LLM: Approximately -5% to +0%
* Reasoning LLM: Approximately -6% to +1%
* **GPQA:**
* Llama3.1-8B: Approximately +5% to +15%
* Llama3.1-70B: Approximately +8% to +18%
* Qwen2.5-7B: Approximately +3% to +10%
* Qwen2.5-72B: Approximately +5% to +15%
* Claude3.5: Approximately +2% to +8%
* GPT-3.5: Approximately +3% to +9%
* GPT-4o: Approximately +7% to +17%
* QWQ-32B: Approximately +4% to +12%
* DeepSeek-v3: Approximately -1% to +4%
* Open LLM: Approximately -2% to +3%
* Closed LLM: Approximately -3% to +2%
* Reasoning LLM: Approximately -4% to +3%
* **AQUA:**
* Llama3.1-8B: Approximately -1% to +4%
* Llama3.1-70B: Approximately +2% to +7%
* Qwen2.5-7B: Approximately -1% to +4%
* Qwen2.5-72B: Approximately +1% to +6%
* Claude3.5: Approximately -1% to +4%
* GPT-3.5: Approximately -1% to +4%
* GPT-4o: Approximately +3% to +8%
* QWQ-32B: Approximately +1% to +6%
* DeepSeek-v3: Approximately -3% to +2%
* Open LLM: Approximately -4% to +1%
* Closed LLM: Approximately -5% to +0%
* Reasoning LLM: Approximately -6% to +1%
* **GSM8K:**
* Llama3.1-8B: Approximately +5% to +15%
* Llama3.1-70B: Approximately +10% to +20%
* Qwen2.5-7B: Approximately +2% to +8%
* Qwen2.5-72B: Approximately +5% to +15%
* Claude3.5: Approximately +1% to +6%
* GPT-3.5: Approximately +2% to +8%
* GPT-4o: Approximately +8% to +18%
* QWQ-32B: Approximately +3% to +10%
* DeepSeek-v3: Approximately -2% to +3%
* Open LLM: Approximately -3% to +2%
* Closed LLM: Approximately -4% to +1%
* Reasoning LLM: Approximately -5% to +2%
* **MATH:**
* Llama3.1-8B: Approximately +5% to +15%
* Llama3.1-70B: Approximately +10% to +20%
* Qwen2.5-7B: Approximately +2% to +8%
* Qwen2.5-72B: Approximately +5% to +15%
* Claude3.5: Approximately +1% to +6%
* GPT-3.5: Approximately +2% to +8%
* GPT-4o: Approximately +8% to +18%
* QWQ-32B: Approximately +3% to +10%
* DeepSeek-v3: Approximately -2% to +3%
* Open LLM: Approximately -3% to +2%
* Closed LLM: Approximately -4% to +1%
* Reasoning LLM: Approximately -5% to +2%
* **HumanEval:**
* Llama3.1-8B: Approximately +2% to +7%
* Llama3.1-70B: Approximately +5% to +10%
* Qwen2.5-7B: Approximately +1% to +5%
* Qwen2.5-72B: Approximately +3% to +8%
* Claude3.5: Approximately +0% to +4%
* GPT-3.5: Approximately +1% to +5%
* GPT-4o: Approximately +4% to +9%
* QWQ-32B: Approximately +2% to +7%
* DeepSeek-v3: Approximately -2% to +3%
* Open LLM: Approximately -3% to +2%
* Closed LLM: Approximately -4% to +1%
* Reasoning LLM: Approximately -5% to +2%
### Key Observations
* Llama3.1-70B consistently outperforms Llama3.1-8B across all datasets.
* GPT-4o generally shows the highest performance gains across most datasets.
* DeepSeek-v3, Open LLM, Closed LLM, and Reasoning LLM often perform near or below the baseline (0%).
* The performance differences between models are more pronounced on datasets like GSM8K and MATH, suggesting these datasets are more sensitive to model capabilities.
* Qwen2.5-72B generally outperforms Qwen2.5-7B.
### Interpretation
The data suggests that model size (as seen with Llama3.1) and architectural advancements (as seen with GPT-4o) significantly impact performance on these benchmark datasets. The consistent underperformance of DeepSeek-v3, Open LLM, Closed LLM, and Reasoning LLM relative to the baseline indicates they may require further development or are less suited for these specific tasks. The larger performance gains on GSM8K and MATH suggest these datasets are more challenging and effectively differentiate between model capabilities, particularly in areas like mathematical reasoning. The plot provides a valuable comparative analysis of LLM performance, highlighting strengths and weaknesses across different domains. The consistent positive Δ (%) for many models indicates that, overall, these LLMs are improving upon previous baseline performance levels.
DECODING INTELLIGENCE...