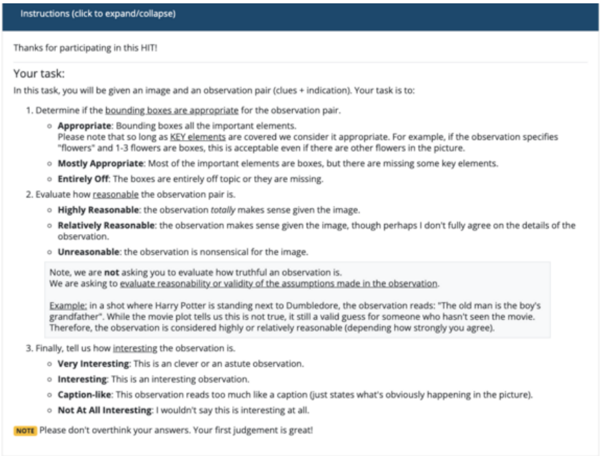
## Screenshot: HIT Task Instructions for Image-Observation Evaluation
### Overview
This image depicts a task instruction page for a Human Intelligence Task (HIT) on Amazon Mechanical Turk. The interface guides workers to evaluate pairs of images and observations by assessing the appropriateness of bounding boxes, the reasonableness of the observation, and the interest level of the observation. The layout includes a collapsible header, structured task steps, an example, and a concluding note.
### Components/Axes
- **Header**: Blue bar with collapsible "Instructions" text.
- **Main Content**:
- **Task Description**: Text outlining the worker's responsibilities.
- **Task Steps**:
1. **Bounding Box Appropriateness**:
- Options: *Appropriate*, *Mostly Appropriate*, *Entirely Off*.
- Criteria: Coverage of key elements (e.g., "flowers" with 1-3 boxes).
2. **Observation Reasonableness**:
- Options: *Highly Reasonable*, *Relatively Reasonable*, *Unreasonable*.
- Criteria: Logical connection between image and observation.
3. **Observation Interest**:
- Options: *Very Interesting*, *Interesting*, *Caption-like*, *Not At All Interesting*.
- **Example**: Textual scenario involving *Harry Potter* and *Dumbledore*.
- **Note**: Yellow-highlighted advisory to avoid overthinking answers.
### Detailed Analysis
- **Bounding Box Appropriateness**:
- *Appropriate*: All key elements are boxed (e.g., "flowers" with 1-3 boxes).
- *Mostly Appropriate*: Most elements boxed but missing some key elements.
- *Entirely Off*: Boxes irrelevant or missing entirely.
- **Observation Reasonableness**:
- *Highly Reasonable*: Observation fully aligns with the image.
- *Relatively Reasonable*: Observation makes partial sense but lacks full agreement on details.
- *Unreasonable*: Observation is nonsensical for the image.
- **Observation Interest**:
- *Very Interesting*: Clever or astute observation.
- *Interesting*: Subjectively engaging observation.
- *Caption-like*: Descriptive but obvious (e.g., "states what’s happening").
- *Not At All Interesting*: Lacks engagement.
### Key Observations
- The task emphasizes **contextual reasoning** (e.g., accepting "mostly appropriate" bounding boxes if key elements are covered).
- The example illustrates **reasonableness evaluation** (e.g., a false observation in a movie context is still valid for uninformed viewers).
- The note discourages overanalysis, prioritizing **intuitive judgments**.
### Interpretation
This task design reflects a crowdsourcing workflow for training or validating computer vision models. Workers are asked to:
1. **Annotate images** by identifying key elements via bounding boxes.
2. **Validate observations** for logical consistency with the image.
3. **Assess engagement** to ensure observations are meaningful or novel.
The example highlights the importance of **contextual awareness** (e.g., distinguishing between factual accuracy and subjective reasonableness). The note suggests the task values **efficiency over perfection**, aligning with real-world scenarios where rapid, intuitive judgments are critical. The structured options reduce ambiguity, ensuring consistent data collection for downstream analysis (e.g., model training or quality control).