\n
## Diagram: Reinforcement Learning System Architecture
### Overview
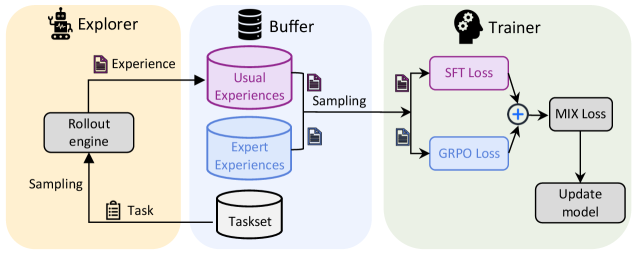
The image depicts a diagram illustrating the architecture of a reinforcement learning system, divided into three main components: an Explorer, a Buffer, and a Trainer. The diagram shows the flow of data and interactions between these components, highlighting the process of experience collection, storage, and model updating.
### Components/Axes
The diagram is segmented into three main areas, each with a distinct background color:
* **Explorer (Yellow):** Contains a "Rollout engine" and receives "Task" input.
* **Buffer (Blue):** Contains "Usual Experiences", "Expert Experiences", and "Taskset".
* **Trainer (Green):** Contains "SFT Loss", "GRPO Loss", "MIX Loss", and "Update model".
Arrows indicate the direction of data flow and interactions between components. Text labels are used to identify each component and the data being processed.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. **Task Input:** A "Task" is sampled and fed into the "Rollout engine" within the Explorer.
2. **Experience Generation:** The "Rollout engine" generates "Experience" based on the task.
3. **Buffer Storage:** The "Experience" is stored in the "Buffer", specifically within "Usual Experiences" and "Expert Experiences" data stores. The "Taskset" is also present within the Buffer.
4. **Sampling from Buffer:** Data is sampled from the "Buffer".
5. **Loss Calculation:** The sampled data is fed into the "Trainer", where "SFT Loss" and "GRPO Loss" are calculated.
6. **Loss Mixing:** The "SFT Loss" and "GRPO Loss" are combined using an addition operation (represented by a plus sign) to produce "MIX Loss".
7. **Model Update:** The "MIX Loss" is used to "Update model" within the Trainer.
The diagram does not contain numerical data or axes. It is a conceptual representation of a system architecture.
### Key Observations
The diagram emphasizes the cyclical nature of reinforcement learning: exploration, experience collection, and model improvement. The separation of "Usual Experiences" and "Expert Experiences" suggests a potential for learning from both standard interactions and demonstrations. The use of separate loss functions ("SFT Loss" and "GRPO Loss") indicates a potentially complex training objective.
### Interpretation
This diagram illustrates a common architecture for reinforcement learning, particularly one that incorporates elements of imitation learning or learning from demonstrations. The "Explorer" represents the agent interacting with the environment, while the "Buffer" serves as a memory for past experiences. The "Trainer" utilizes these experiences to refine the agent's policy. The distinction between "Usual Experiences" and "Expert Experiences" suggests a hybrid approach where the agent learns both through trial-and-error and by observing expert behavior. The "SFT Loss" and "GRPO Loss" likely represent different components of the overall training objective, potentially related to supervised fine-tuning (SFT) and reinforcement learning with a specific reward function (GRPO). The "MIX Loss" combines these components to guide the model update process. The diagram highlights the importance of efficient experience replay and the careful design of loss functions in achieving successful reinforcement learning.