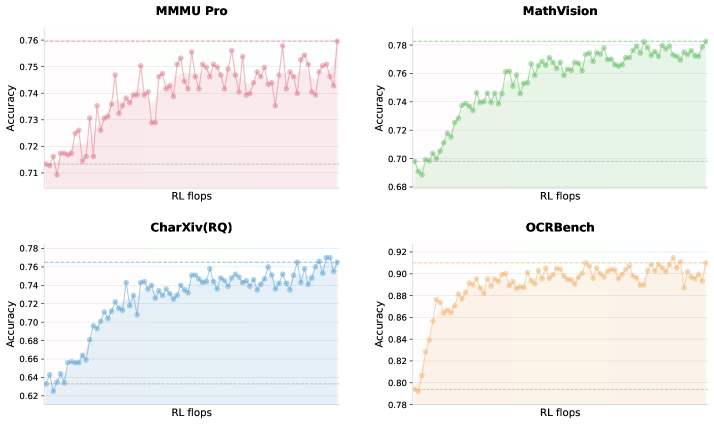
## Line Charts: Model Accuracy vs. RL Flops
### Overview
The image displays four separate line charts arranged in a 2x2 grid. Each chart plots the "Accuracy" of a different model or benchmark against "RL flops" (Reinforcement Learning floating-point operations). The charts illustrate how performance changes with increased computational training effort. All charts share the same x-axis label but have different y-axis scales and data trends.
### Components/Axes
* **Common Elements:**
* **X-axis (All Charts):** Labeled "RL flops". The axis represents a progression of increasing computational effort, though specific numerical markers are not visible.
* **Y-axis (All Charts):** Labeled "Accuracy". The scale and range differ for each chart.
* **Chart Type:** Line chart with data points marked by small circles. Each chart uses a distinct color for its line and a light shaded area beneath it.
* **Individual Chart Details (Spatial Grounding):**
1. **Top-Left Chart: "MMMU Pro"**
* **Title:** "MMMU Pro" (centered at top).
* **Y-axis Scale:** Ranges from approximately 0.71 to 0.76. Major gridlines are visible at 0.71, 0.72, 0.73, 0.74, 0.75, 0.76.
* **Line Color:** Red.
2. **Top-Right Chart: "MathVision"**
* **Title:** "MathVision" (centered at top).
* **Y-axis Scale:** Ranges from approximately 0.68 to 0.78. Major gridlines are visible at 0.68, 0.70, 0.72, 0.74, 0.76, 0.78.
* **Line Color:** Green.
3. **Bottom-Left Chart: "CharXiv(RQ)"**
* **Title:** "CharXiv(RQ)" (centered at top).
* **Y-axis Scale:** Ranges from approximately 0.62 to 0.78. Major gridlines are visible at 0.62, 0.64, 0.66, 0.68, 0.70, 0.72, 0.74, 0.76, 0.78.
* **Line Color:** Blue.
4. **Bottom-Right Chart: "OCRBench"**
* **Title:** "OCRBench" (centered at top).
* **Y-axis Scale:** Ranges from approximately 0.78 to 0.92. Major gridlines are visible at 0.78, 0.80, 0.82, 0.84, 0.86, 0.88, 0.90, 0.92.
* **Line Color:** Orange.
### Detailed Analysis
* **MMMU Pro (Red Line - Top-Left):**
* **Trend Verification:** The line shows a general upward trend with significant volatility. It starts low, rises sharply, then enters a phase of high-frequency oscillation within a band.
* **Data Points (Approximate):** Begins near 0.715. Shows a steep climb to ~0.745. The majority of subsequent data points fluctuate between ~0.735 and ~0.755, with a final point near the top of the range at ~0.76.
* **MathVision (Green Line - Top-Right):**
* **Trend Verification:** Shows a strong, consistent upward trend that begins to plateau in the latter half.
* **Data Points (Approximate):** Starts at the lowest point on its chart, ~0.69. Climbs steadily, crossing 0.74 and 0.76. The trend flattens in the upper region, with most later points oscillating between ~0.77 and ~0.78.
* **CharXiv(RQ) (Blue Line - Bottom-Left):**
* **Trend Verification:** Exhibits a very clear and steady upward trend with moderate noise.
* **Data Points (Approximate):** Begins at the lowest value across all charts, ~0.62. Shows a consistent rise, passing through 0.66, 0.70, and 0.74. The final data points are near ~0.77.
* **OCRBench (Orange Line - Bottom-Right):**
* **Trend Verification:** Demonstrates a rapid initial ascent followed by a stable plateau with minor fluctuations.
* **Data Points (Approximate):** Starts at ~0.79. Increases very quickly to ~0.88. The line then stabilizes, with the majority of points oscillating in a narrow band between ~0.89 and ~0.91. The final point is slightly lower, near ~0.90.
### Key Observations
1. **Universal Improvement:** All four benchmarks show a positive correlation between "RL flops" and "Accuracy," indicating that increased computational training generally improves model performance on these tasks.
2. **Performance Ceiling & Volatility:** Each model appears to approach a performance ceiling. MMMU Pro shows the most volatile plateau, while OCRBench shows the most stable one.
3. **Benchmark Difficulty:** The starting and ending accuracy values suggest varying difficulty. CharXiv(RQ) starts lowest (~0.62), implying it may be the most challenging task initially. OCRBench reaches the highest absolute accuracy (~0.91), suggesting models achieve higher proficiency on this task relative to the others.
4. **Learning Rate:** The slope of the initial ascent varies. OCRBench and MathVision show very steep initial learning curves, while CharXiv(RQ) has a more gradual, sustained climb.
### Interpretation
This composite figure likely comes from a research paper or technical report evaluating the scaling laws of a vision-language model or a reinforcement learning process. The data suggests that:
* **Investment Pays Off:** Allocating more computational resources (RL flops) during training yields measurable accuracy gains across diverse multimodal benchmarks (visual reasoning, math, chart understanding, OCR).
* **Task-Specific Scaling:** The model's learning dynamics are task-dependent. Some tasks (like OCRBench) are mastered quickly and then refined, while others (like CharXiv(RQ)) show continuous, steady improvement, indicating they may require more data or complexity to master.
* **Stability vs. Volatility:** The stability of the plateau (e.g., OCRBench vs. MMMU Pro) may reflect the nature of the task. Noisy tasks with less clear-cut answers might lead to more volatile performance metrics even after extensive training.
* **Practical Implication:** For a practitioner, this chart helps decide the optimal training budget. For example, training beyond a certain point for OCRBench yields diminishing returns, whereas for CharXiv(RQ), further investment might still be beneficial. The charts provide a visual cost-benefit analysis for scaling training compute.