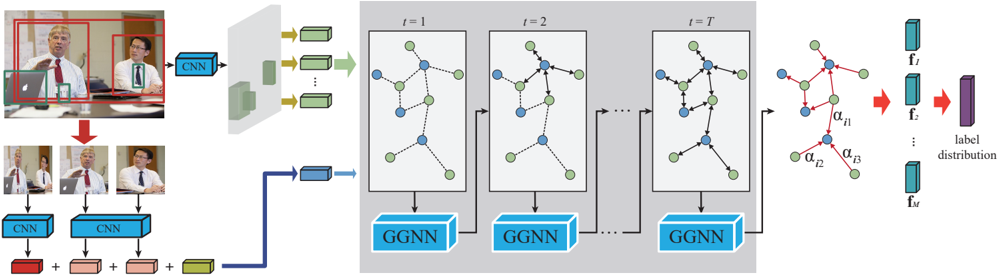
## Flowchart: Video Analysis Pipeline with Temporal Graph Neural Networks
### Overview
The diagram illustrates a multi-stage pipeline for processing video data, combining Convolutional Neural Networks (CNNs) for spatial feature extraction and Graph Neural Networks (GNNs) for temporal modeling. The workflow begins with input images of a meeting scenario, progresses through sequential processing stages, and concludes with a label distribution output.
### Components/Axes
1. **Input Stage**:
- Two overlapping images of a meeting scenario with:
- Red bounding boxes highlighting two individuals (spatial regions of interest)
- Green bounding boxes marking objects (e.g., laptops)
- Three smaller images showing cropped views of the same individuals
2. **Processing Stages**:
- **CNN Blocks**: Three parallel CNN modules processing different input regions
- **GGNN Blocks**: Three sequential Graph Neural Network modules labeled:
- `t=1` (initial time step)
- `t=2` (intermediate time step)
- `t=T` (final time step)
- **Label Distribution**: Final output showing probability distribution across labels
3. **Visual Elements**:
- Node colors:
- Blue: Feature nodes
- Green: Temporal nodes
- Edge types:
- Solid lines: Spatial connections
- Dashed lines: Temporal connections
- Greek letters (α₁₁, α₁₂, α₁₃): Attention weights between nodes
### Detailed Analysis
1. **Spatial Processing**:
- CNNs extract features from:
- Person 1 (red box)
- Person 2 (green box)
- Objects (green box)
- Feature maps represented as 3D blocks with directional arrows
2. **Temporal Modeling**:
- GGNNs process features across time steps:
- `t=1`: Initial feature aggregation
- `t=2`: Intermediate temporal fusion
- `t=T`: Final temporal integration
- Graph structure evolves with:
- Node connections changing across time steps
- Attention weights (α) modulating node interactions
3. **Output**:
- Label distribution visualized as stacked bars with:
- Cyan blocks representing feature vectors (f₁ to fₘ)
- Purple block showing final label probabilities
### Key Observations
1. **Temporal Dependency**: The sequential GGNN blocks suggest modeling of long-term dependencies in video data
2. **Multi-modal Input**: Combines spatial (CNN) and temporal (GGNN) processing for comprehensive analysis
3. **Attention Mechanism**: Presence of α weights indicates dynamic node interactions based on feature importance
4. **Label Uncertainty**: Stacked bar visualization implies probabilistic output rather than deterministic classification
### Interpretation
This architecture demonstrates a hybrid approach for video understanding tasks:
- **CNN-GGNN Integration**: Combines spatial feature extraction with temporal graph modeling
- **Temporal Graph Dynamics**: The evolving graph structure across time steps captures sequential relationships
- **Attention-Based Processing**: The α weights suggest the model learns to focus on relevant node interactions
- **Probabilistic Output**: The label distribution indicates confidence scores for multiple classes
The pipeline appears designed for tasks like action recognition or speaker identification in meetings, where both spatial context (individuals/objects) and temporal dynamics (interactions over time) are critical. The use of multiple time steps (t=1 to t=T) suggests the model can handle variable-length sequences, making it suitable for real-world video analysis where events have different durations.