\n
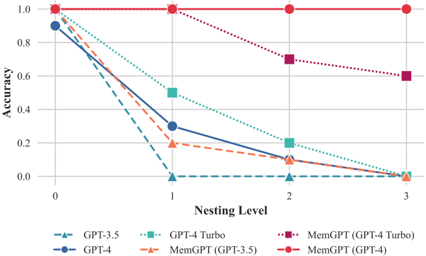
## Line Chart: Accuracy vs. Nesting Level for Different Models
### Overview
This line chart depicts the relationship between nesting level and accuracy for several language models: GPT-3.5, GPT-4, GPT-4 Turbo, and MemGPT utilizing both GPT-3.5 and GPT-4 backends. The x-axis represents the nesting level, ranging from 0 to 3, while the y-axis represents accuracy, ranging from 0 to 1.0.
### Components/Axes
* **X-axis Title:** Nesting Level
* **Y-axis Title:** Accuracy
* **X-axis Markers:** 0, 1, 2, 3
* **Y-axis Markers:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
* **Legend:** Located in the top-center of the chart.
* GPT-3.5 (Light Blue Triangle Markers)
* GPT-4 (Dark Blue Circle Markers)
* GPT-4 Turbo (Teal Square Markers)
* MemGPT (GPT-3.5) (Orange Triangle Markers)
* MemGPT (GPT-4 Turbo) (Purple Diamond Markers)
* MemGPT (GPT-4) (Red Circle Markers)
### Detailed Analysis
* **GPT-3.5 (Light Blue):** The line slopes downward sharply from Nesting Level 0 to 1, then continues to decrease, but at a slower rate, from Nesting Level 1 to 3.
* Nesting Level 0: Approximately 0.92 accuracy.
* Nesting Level 1: Approximately 0.08 accuracy.
* Nesting Level 2: Approximately 0.04 accuracy.
* Nesting Level 3: Approximately 0.02 accuracy.
* **GPT-4 (Dark Blue):** The line slopes downward significantly from Nesting Level 0 to 1, then continues to decrease, but at a slower rate, from Nesting Level 1 to 3.
* Nesting Level 0: Approximately 0.88 accuracy.
* Nesting Level 1: Approximately 0.32 accuracy.
* Nesting Level 2: Approximately 0.12 accuracy.
* Nesting Level 3: Approximately 0.06 accuracy.
* **GPT-4 Turbo (Teal):** The line slopes downward from Nesting Level 0 to 1, then decreases more slowly from Nesting Level 1 to 3.
* Nesting Level 0: Approximately 0.90 accuracy.
* Nesting Level 1: Approximately 0.52 accuracy.
* Nesting Level 2: Approximately 0.24 accuracy.
* Nesting Level 3: Approximately 0.10 accuracy.
* **MemGPT (GPT-3.5) (Orange):** The line slopes downward rapidly from Nesting Level 0 to 1, then decreases more slowly from Nesting Level 1 to 3.
* Nesting Level 0: Approximately 0.85 accuracy.
* Nesting Level 1: Approximately 0.24 accuracy.
* Nesting Level 2: Approximately 0.08 accuracy.
* Nesting Level 3: Approximately 0.04 accuracy.
* **MemGPT (GPT-4 Turbo) (Purple):** The line is relatively flat, decreasing slightly from Nesting Level 0 to 3.
* Nesting Level 0: Approximately 1.0 accuracy.
* Nesting Level 1: Approximately 0.72 accuracy.
* Nesting Level 2: Approximately 1.0 accuracy.
* Nesting Level 3: Approximately 0.64 accuracy.
* **MemGPT (GPT-4) (Red):** The line is flat, remaining at approximately 1.0 accuracy across all nesting levels.
* Nesting Level 0: Approximately 1.0 accuracy.
* Nesting Level 1: Approximately 1.0 accuracy.
* Nesting Level 2: Approximately 1.0 accuracy.
* Nesting Level 3: Approximately 1.0 accuracy.
### Key Observations
* MemGPT with GPT-4 maintains near-perfect accuracy across all nesting levels, significantly outperforming other models.
* GPT-3.5 and MemGPT (GPT-3.5) experience the most significant drop in accuracy as nesting level increases.
* GPT-4 and GPT-4 Turbo show a moderate decrease in accuracy with increasing nesting levels.
* MemGPT (GPT-4 Turbo) shows a slight decrease in accuracy with increasing nesting levels, but remains relatively high.
### Interpretation
The data suggests that the ability of language models to maintain accuracy degrades as the complexity of the task (represented by nesting level) increases. MemGPT, when paired with GPT-4, demonstrates a remarkable ability to handle increased nesting levels without significant performance loss, indicating a robust architecture for complex reasoning tasks. The stark contrast between MemGPT (GPT-4) and other models highlights the importance of the underlying language model's capabilities in maintaining performance in complex scenarios. The rapid decline in accuracy for GPT-3.5 and MemGPT (GPT-3.5) suggests that these models struggle with tasks requiring deeper reasoning or memory recall as nesting levels increase. The relatively stable performance of MemGPT (GPT-4 Turbo) suggests that it is more capable than GPT-4 and GPT-3.5, but still falls short of the performance of MemGPT (GPT-4). This could be due to differences in model size, training data, or architectural design. The flat line for MemGPT (GPT-4) is an outlier, suggesting that this combination is exceptionally well-suited for handling nested tasks, potentially due to the model's ability to effectively manage and utilize its internal memory.