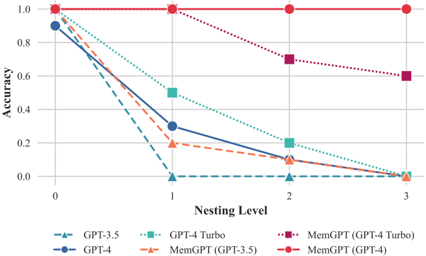
## Line Chart: Model Accuracy Across Nesting Levels
### Overview
This is a line chart comparing the performance (accuracy) of six different language models across four increasing levels of task complexity, defined as "Nesting Level." The chart demonstrates how accuracy degrades for most models as the nesting level increases, with one model maintaining perfect performance.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Nesting Level." It has four discrete, equally spaced tick marks labeled: `0`, `1`, `2`, `3`.
* **Y-Axis (Vertical):** Labeled "Accuracy." It is a linear scale ranging from `0.0` to `1.0`, with major tick marks at `0.0`, `0.2`, `0.4`, `0.6`, `0.8`, and `1.0`.
* **Legend:** Positioned at the bottom of the chart, centered horizontally. It contains six entries, each pairing a line style/color with a model name:
1. `GPT-3.5`: Blue dashed line with upward-pointing triangle markers.
2. `GPT-4`: Dark blue solid line with circle markers.
3. `GPT-4-Turbo`: Teal dotted line with square markers.
4. `MemGPT (GPT-3.5)`: Orange dashed line with upward-pointing triangle markers.
5. `MemGPT (GPT-4 Turbo)`: Purple dotted line with square markers.
6. `MemGPT (GPT-4)`: Red solid line with circle markers.
### Detailed Analysis
The chart plots accuracy values for each model at each nesting level. The following data points are approximate, derived from visual inspection of the chart.
**Trend Verification & Data Points:**
1. **GPT-3.5 (Blue dashed line, triangle markers):**
* **Trend:** Sharp, near-linear decline from high accuracy to zero.
* **Points:** Level 0: ~0.92, Level 1: ~0.0, Level 2: ~0.0, Level 3: ~0.0.
2. **GPT-4 (Dark blue solid line, circle markers):**
* **Trend:** Steep decline, similar to GPT-3.5 but starting slightly higher.
* **Points:** Level 0: ~0.92, Level 1: ~0.30, Level 2: ~0.10, Level 3: ~0.0.
3. **GPT-4-Turbo (Teal dotted line, square markers):**
* **Trend:** Declines steadily but less steeply than GPT-4.
* **Points:** Level 0: ~0.92, Level 1: ~0.50, Level 2: ~0.20, Level 3: ~0.0.
4. **MemGPT (GPT-3.5) (Orange dashed line, triangle markers):**
* **Trend:** Declines from a lower starting point than its base model.
* **Points:** Level 0: ~0.92, Level 1: ~0.20, Level 2: ~0.10, Level 3: ~0.0.
5. **MemGPT (GPT-4 Turbo) (Purple dotted line, square markers):**
* **Trend:** Declines gradually, maintaining the highest accuracy among non-perfect models at higher levels.
* **Points:** Level 0: ~1.0, Level 1: ~1.0, Level 2: ~0.70, Level 3: ~0.60.
6. **MemGPT (GPT-4) (Red solid line, circle markers):**
* **Trend:** Perfectly flat, horizontal line at maximum accuracy.
* **Points:** Level 0: 1.0, Level 1: 1.0, Level 2: 1.0, Level 3: 1.0.
### Key Observations
* **Universal Starting Point:** All models except `MemGPT (GPT-4 Turbo)` begin at approximately the same accuracy (~0.92) at Nesting Level 0. `MemGPT (GPT-4 Turbo)` starts at a perfect 1.0.
* **Performance Collapse:** The standard `GPT-3.5` model's accuracy collapses to near zero immediately at Nesting Level 1.
* **MemGPT (GPT-4) Anomaly:** The `MemGPT (GPT-4)` model is a complete outlier, showing no degradation in accuracy across all tested nesting levels.
* **MemGPT Efficacy:** For both GPT-4 Turbo and GPT-4, the MemGPT variant significantly outperforms the base model at higher nesting levels (2 and 3). For GPT-3.5, the MemGPT variant shows a different, but still declining, trajectory.
* **Convergence at Zero:** By Nesting Level 3, all models except the two MemGPT-enhanced GPT-4 variants (`MemGPT (GPT-4 Turbo)` and `MemGPT (GPT-4)`) have converged to an accuracy of approximately 0.0.
### Interpretation
This chart presents a compelling case for the effectiveness of the "MemGPT" architecture in maintaining model performance on tasks requiring hierarchical or nested reasoning. The "Nesting Level" likely represents increasing complexity in task structure (e.g., depth of reasoning steps, number of embedded sub-tasks).
The data suggests that standard LLMs, even powerful ones like GPT-4, suffer severe performance degradation as task complexity increases along this nesting dimension. The MemGPT modification appears to mitigate this degradation substantially. The perfect performance of `MemGPT (GPT-4)` implies that, for this specific benchmark, the combination of the GPT-4 base model with the MemGPT architecture creates a system robust to the tested levels of nesting complexity. This has significant implications for deploying AI in domains requiring multi-step, structured reasoning, such as complex planning, advanced coding, or layered analytical tasks. The chart effectively argues that architectural enhancements for memory and context management (as implied by "MemGPT") may be as crucial as raw model scale for tackling complex cognitive tasks.