TECHNICAL ASSET FINGERPRINT
71bb044fad71c54a028ca43f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
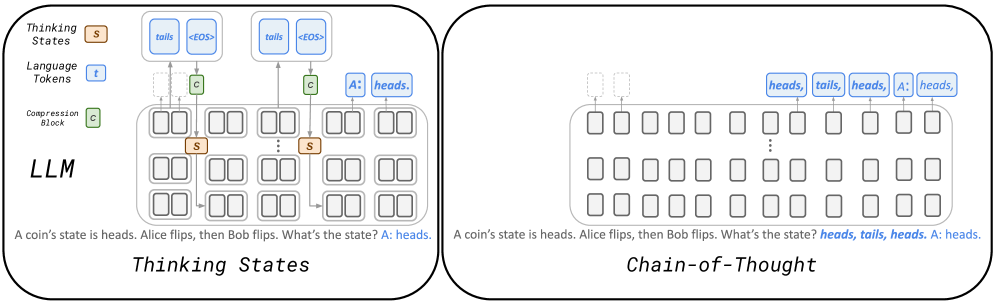
## Diagram: Comparison of "Thinking States" vs. "Chain-of-Thought" in an LLM
### Overview
The image is a technical diagram comparing two different internal processing methods for a Large Language Model (LLM) when solving a simple logic problem. It is split into two distinct panels, each illustrating a different approach: "Thinking States" on the left and "Chain-of-Thought" on the right. Both panels use the same input prompt and arrive at the same final answer, but the internal mechanisms depicted are fundamentally different.
### Components/Axes
The diagram is not a chart with axes but a schematic with labeled components.
**Legend (Top-Left of Left Panel):**
* **Thinking States (S):** Represented by an orange square with a white "S".
* **Language Tokens (T):** Represented by a blue square with a white "T".
* **Compression Block (C):** Represented by a green square with a white "C".
**Left Panel: "Thinking States"**
* **Title:** "Thinking States" (bottom center).
* **Main Component:** A large, rounded rectangle labeled **"LLM"** in the center-left.
* **Internal Structure:** The LLM contains a grid of smaller, empty rounded rectangles, representing layers or processing units.
* **Data Flow:**
1. **Input Text (Bottom):** "A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads."
2. **Processing:** Arrows show data flowing from the input text into the LLM. Inside, orange "S" (Thinking State) blocks are connected to green "C" (Compression Block) blocks.
3. **Output Generation:** Arrows lead from the internal "C" blocks to blue "T" (Language Token) blocks at the top. These tokens form the output sequence: `tails`, `<EOS>`, `tails`, `<EOS>`, and finally `A: heads.`.
* **Spatial Layout:** The legend is in the top-left corner. The LLM block dominates the center. Input text is at the bottom, and output tokens are at the top.
**Right Panel: "Chain-of-Thought"**
* **Title:** "Chain-of-Thought" (bottom center).
* **Main Component:** A large, rounded rectangle (similar to the LLM block but unlabeled) in the center.
* **Internal Structure:** A grid of empty rounded rectangles, similar to the left panel but without any internal "S" or "C" blocks.
* **Data Flow:**
1. **Input Text (Bottom):** Identical to the left panel: "A coin's state is heads. Alice flips, then Bob flips. What's the state? **heads, tails, heads.** A: heads." (Note: The intermediate reasoning steps are now part of the input text in bold).
2. **Processing:** No internal state or compression blocks are shown. The flow is direct.
3. **Output Generation:** A single sequence of blue "T" (Language Token) blocks is generated at the top: `heads`, `tails`, `heads`, `A: heads.`.
* **Spatial Layout:** Mirrors the left panel. The LLM-like block is central, input text at the bottom, and output tokens are at the top.
### Detailed Analysis
The diagram contrasts two paradigms for LLM reasoning:
1. **Thinking States (Left):**
* **Mechanism:** The model uses dedicated internal components—**Thinking States (S)** and **Compression Blocks (C)**—to process the problem. These are separate from the final language token generation pathway.
* **Process:** The input is processed through these internal states, which likely perform abstract reasoning or intermediate computation. The results are then "compressed" and finally translated into output language tokens.
* **Output:** The final output is a direct answer (`A: heads.`). The intermediate reasoning steps (`tails`, `<EOS>`) are generated as separate, internal tokens that are not presented as part of the final coherent answer to the user.
2. **Chain-of-Thought (Right):**
* **Mechanism:** The model relies on generating a sequence of explicit language tokens that form a reasoning trace. There are no depicted specialized internal state blocks.
* **Process:** The reasoning steps (`heads, tails, heads.`) are generated as part of the language token stream itself, appended to the original question in the input context for the final answer generation.
* **Output:** The final output includes the explicit reasoning chain followed by the answer (`A: heads.`). The "thought" process is visible in the token sequence.
### Key Observations
* **Identical Problem & Answer:** Both panels use the exact same logic puzzle (two coin flips starting from heads) and arrive at the correct answer: "heads."
* **Divergent Internal Representation:** The core difference is architectural. "Thinking States" implies a hidden, non-linguistic reasoning layer, while "Chain-of-Thought" uses the language modeling process itself to reason step-by-step.
* **Token Usage:** The "Thinking States" panel shows the generation of `<EOS>` (End of Sequence) tokens internally, suggesting segmented processing. The "Chain-of-Thought" panel shows a continuous stream of meaningful tokens.
* **Input Context:** In the Chain-of-Thought panel, the reasoning steps are explicitly included in the input text (shown in bold), indicating they are part of the prompt for the final answer step.
### Interpretation
This diagram illustrates a fundamental design choice in AI reasoning systems.
* **What it demonstrates:** It contrasts **internal, abstract computation** ("Thinking States") with **externalized, linguistic reasoning** ("Chain-of-Thought"). The former suggests a model that "thinks" in a proprietary, compressed format before speaking. The latter suggests a model that "thinks out loud" using the same language it uses to communicate.
* **Relationship between elements:** The "Thinking States" components (S, C) are positioned as intermediaries between raw input and final output, acting as a black-box reasoning engine. In "Chain-of-Thought," the reasoning is not an intermediate component but a direct, linear part of the input-output sequence.
* **Implications:** The "Thinking States" approach could be more efficient (processing compressed states) but less interpretable. The "Chain-of-Thought" approach is highly interpretable (you can see the reasoning steps) but may be less efficient as it requires generating many more tokens. The diagram suggests that both pathways can solve the same problem, highlighting that the *process* of reasoning in LLMs can be architecturally distinct from the *presentation* of reasoning. The presence of the same LLM grid in both panels implies the same base model could potentially support both modes of operation.
DECODING INTELLIGENCE...