\n
## Charts: Training Performance Comparison
### Overview
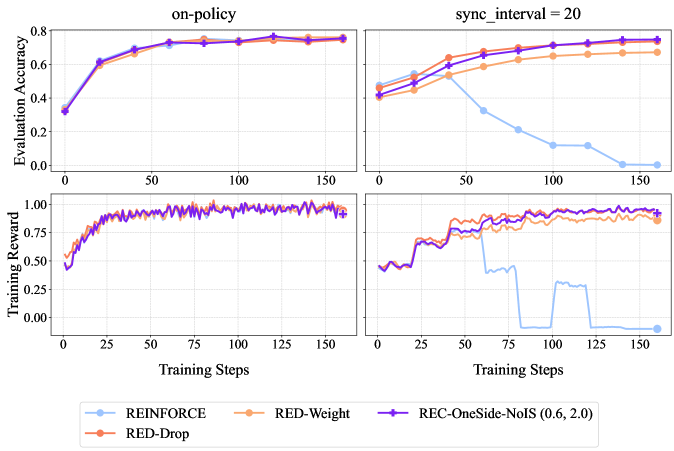
The image presents a comparison of training performance for different reinforcement learning algorithms. It consists of two columns of charts, one labeled "on-policy" and the other "sync_interval = 20". Each column contains two charts: one displaying "Evaluation Accuracy" versus "Training Steps", and the other displaying "Training Reward" versus "Training Steps". Four algorithms are compared: REINFORCE, RED-Weight, RED-Drop, and REC-OneSide-NoIS (0.6, 2.0).
### Components/Axes
* **X-axis (both charts):** Training Steps, ranging from 0 to 150.
* **Y-axis (top charts):** Evaluation Accuracy, ranging from 0 to 0.8.
* **Y-axis (bottom charts):** Training Reward, ranging from 0 to 1.0.
* **Legend:** Located at the bottom center of the image.
* REINFORCE (Light Blue)
* RED-Weight (Orange)
* REC-OneSide-NoIS (0.6, 2.0) (Purple)
* RED-Drop (Brown)
### Detailed Analysis or Content Details
**On-Policy Column:**
* **Evaluation Accuracy:**
* REINFORCE (Light Blue): Starts at approximately 0.15, increases rapidly to around 0.65 by step 25, and plateaus around 0.7 with minor fluctuations.
* RED-Weight (Orange): Starts at approximately 0.15, increases to around 0.5 by step 25, and plateaus around 0.6 with minor fluctuations.
* REC-OneSide-NoIS (0.6, 2.0) (Purple): Starts at approximately 0.15, increases steadily to around 0.7 by step 50, and remains relatively stable around 0.7.
* RED-Drop (Brown): Starts at approximately 0.15, increases to around 0.5 by step 25, and plateaus around 0.6 with minor fluctuations.
* **Training Reward:**
* REINFORCE (Light Blue): Fluctuates around 0.8-0.9 throughout the training process.
* RED-Weight (Orange): Fluctuates around 0.8-0.9 throughout the training process.
* REC-OneSide-NoIS (0.6, 2.0) (Purple): Fluctuates around 0.7-0.9 throughout the training process, with a dip around step 25.
* RED-Drop (Brown): Fluctuates around 0.7-0.9 throughout the training process.
**Sync\_interval = 20 Column:**
* **Evaluation Accuracy:**
* REINFORCE (Light Blue): Starts at approximately 0.2, increases to around 0.5 by step 50, and then declines to around 0.2 by step 150.
* RED-Weight (Orange): Starts at approximately 0.4, increases to around 0.6 by step 50, and then declines to around 0.3 by step 150.
* REC-OneSide-NoIS (0.6, 2.0) (Purple): Starts at approximately 0.4, increases to around 0.7 by step 50, and remains relatively stable around 0.6-0.7.
* RED-Drop (Brown): Starts at approximately 0.4, increases to around 0.6 by step 50, and then declines sharply to around 0.1 by step 150.
* **Training Reward:**
* REINFORCE (Light Blue): Fluctuates around 0.7-0.8 throughout the training process.
* RED-Weight (Orange): Fluctuates around 0.8-0.9 throughout the training process.
* REC-OneSide-NoIS (0.6, 2.0) (Purple): Fluctuates around 0.7-0.8 throughout the training process.
* RED-Drop (Brown): Exhibits a large drop in reward around step 75, falling from approximately 0.8 to 0.0, and remains low for the rest of the training process.
### Key Observations
* In the "on-policy" setting, all algorithms achieve relatively high and stable evaluation accuracy and training reward. REINFORCE and REC-OneSide-NoIS perform slightly better in terms of evaluation accuracy.
* In the "sync\_interval = 20" setting, the performance of REINFORCE and RED-Drop deteriorates significantly over time, while REC-OneSide-NoIS maintains a relatively stable performance. RED-Weight also shows a decline, but less drastic than REINFORCE and RED-Drop.
* RED-Drop exhibits a catastrophic failure in the "sync\_interval = 20" setting, with a sudden drop in both evaluation accuracy and training reward around step 75.
### Interpretation
The charts demonstrate the impact of the synchronization interval on the training performance of different reinforcement learning algorithms. In the "on-policy" setting, where updates are applied immediately, all algorithms perform reasonably well. However, when a synchronization interval of 20 is introduced, the performance of REINFORCE and RED-Drop degrades significantly, suggesting that these algorithms are sensitive to delayed updates.
REC-OneSide-NoIS appears to be more robust to delayed updates, maintaining a stable performance even with a synchronization interval of 20. This could be due to the noise injection mechanism, which helps to prevent overfitting and improve generalization. The catastrophic failure of RED-Drop in the "sync\_interval = 20" setting suggests that this algorithm is particularly vulnerable to the effects of delayed updates, potentially due to instability in the learning process.
The difference in performance between the two settings highlights the importance of considering the synchronization interval when designing and training reinforcement learning algorithms. The choice of synchronization interval should be based on the specific characteristics of the algorithm and the environment.