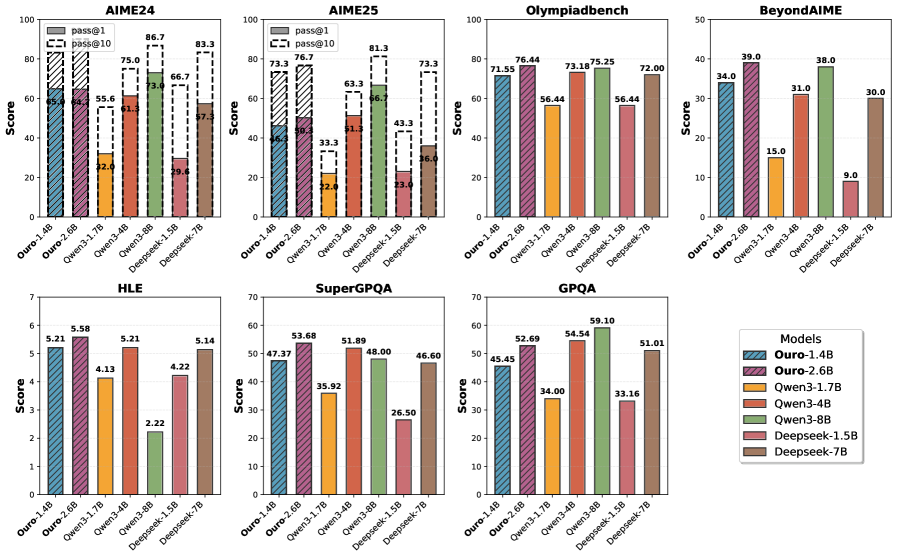
## Bar Charts: Model Performance on Various Benchmarks
### Overview
The image presents a series of bar charts comparing the performance of different language models on various benchmarks: AIME24, AIME25, Olympiadbench, BeyondAIME, HLE, SuperGPQA, and GPQA. The charts display the "Score" achieved by each model on each benchmark. The models being compared are Ouro-1.4B, Ouro-2.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Deepseek-1.5B, and Deepseek-7B. A legend in the bottom-right corner associates each model with a specific color. For AIME24 and AIME25, the charts also show "pass@1" and "pass@10" metrics.
### Components/Axes
* **Titles:** Each chart has a title indicating the benchmark name (e.g., "AIME24", "Olympiadbench").
* **Y-axis:** Labeled "Score," ranging from 0 to 100 for AIME24, AIME25, and Olympiadbench; 0 to 50 for BeyondAIME; 0 to 7 for HLE; 0 to 70 for SuperGPQA; and 0 to 60 for GPQA.
* **X-axis:** Represents the different language models being compared: Ouro-1.4B, Ouro-2.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Deepseek-1.5B, and Deepseek-7B.
* **Legend:** Located in the bottom-right corner, mapping model names to colors.
* Ouro-1.4B: Blue with diagonal lines
* Ouro-2.6B: Purple with diagonal lines
* Qwen3-1.7B: Yellow-Orange
* Qwen3-4B: Red-Orange
* Qwen3-8B: Green
* Deepseek-1.5B: Light Red
* Deepseek-7B: Brown
* **Additional Metrics (AIME24 and AIME25):** "pass@1" and "pass@10" are represented by stacked bars on top of the main score bars. "pass@1" is represented by a solid white bar, and "pass@10" is represented by a white bar with black diagonal lines.
### Detailed Analysis
**AIME24:**
* Ouro-1.4B: Score approximately 65.0, pass@1 approximately 70, pass@10 approximately 80.
* Ouro-2.6B: Score approximately 64.0, pass@1 approximately 75, pass@10 approximately 87.
* Qwen3-1.7B: Score approximately 32.0, pass@1 approximately 60, pass@10 approximately 73.
* Qwen3-4B: Score approximately 61.0, pass@1 approximately 65, pass@10 approximately 75.
* Qwen3-8B: Score approximately 73.0, pass@1 approximately 75, pass@10 approximately 87.
* Deepseek-1.5B: Score approximately 29.0, pass@1 approximately 50, pass@10 approximately 67.
* Deepseek-7B: Score approximately 57.0, pass@1 approximately 60, pass@10 approximately 83.
**AIME25:**
* Ouro-1.4B: Score approximately 46.0, pass@1 approximately 60, pass@10 approximately 73.
* Ouro-2.6B: Score approximately 50.0, pass@1 approximately 65, pass@10 approximately 77.
* Qwen3-1.7B: Score approximately 22.0, pass@1 approximately 30, pass@10 approximately 63.
* Qwen3-4B: Score approximately 51.0, pass@1 approximately 60, pass@10 approximately 67.
* Qwen3-8B: Score approximately 67.0, pass@1 approximately 70, pass@10 approximately 81.
* Deepseek-1.5B: Score approximately 23.0, pass@1 approximately 35, pass@10 approximately 43.
* Deepseek-7B: Score approximately 36.0, pass@1 approximately 50, pass@10 approximately 73.
**Olympiadbench:**
* Ouro-1.4B: Score approximately 71.55
* Ouro-2.6B: Score approximately 76.44
* Qwen3-1.7B: Score approximately 56.44
* Qwen3-4B: Score approximately 73.18
* Qwen3-8B: Score approximately 75.25
* Deepseek-1.5B: Score approximately 56.44
* Deepseek-7B: Score approximately 72.00
**BeyondAIME:**
* Ouro-1.4B: Score approximately 34.0
* Ouro-2.6B: Score approximately 39.0
* Qwen3-1.7B: Score approximately 15.0
* Qwen3-4B: Score approximately 31.0
* Qwen3-8B: Score approximately 38.0
* Deepseek-1.5B: Score approximately 9.0
* Deepseek-7B: Score approximately 30.0
**HLE:**
* Ouro-1.4B: Score approximately 5.21
* Ouro-2.6B: Score approximately 5.58
* Qwen3-1.7B: Score approximately 4.13
* Qwen3-4B: Score approximately 5.21
* Qwen3-8B: Score approximately 2.22
* Deepseek-1.5B: Score approximately 4.22
* Deepseek-7B: Score approximately 5.14
**SuperGPQA:**
* Ouro-1.4B: Score approximately 47.37
* Ouro-2.6B: Score approximately 53.68
* Qwen3-1.7B: Score approximately 35.92
* Qwen3-4B: Score approximately 51.89
* Qwen3-8B: Score approximately 48.00
* Deepseek-1.5B: Score approximately 26.50
* Deepseek-7B: Score approximately 46.60
**GPQA:**
* Ouro-1.4B: Score approximately 45.45
* Ouro-2.6B: Score approximately 52.69
* Qwen3-1.7B: Score approximately 34.00
* Qwen3-4B: Score approximately 54.54
* Qwen3-8B: Score approximately 59.10
* Deepseek-1.5B: Score approximately 33.16
* Deepseek-7B: Score approximately 51.01
### Key Observations
* **Olympiadbench:** Ouro-2.6B and Qwen3-8B show the highest scores.
* **BeyondAIME:** Ouro-2.6B and Qwen3-8B perform relatively well, while Deepseek-1.5B has the lowest score.
* **HLE:** Scores are generally close, with Ouro-2.6B showing a slightly higher score. Qwen3-8B performs the worst.
* **SuperGPQA:** Ouro-2.6B and Qwen3-4B achieve relatively high scores, while Deepseek-1.5B performs poorly.
* **GPQA:** Qwen3-8B has the highest score, while Qwen3-1.7B has the lowest.
* **AIME24 and AIME25:** The "pass@1" and "pass@10" metrics are consistently higher than the base "Score" for all models.
### Interpretation
The bar charts provide a comparative analysis of the performance of different language models across a range of benchmarks. The models exhibit varying strengths and weaknesses depending on the specific task. Ouro-2.6B and Qwen3-8B generally perform well across multiple benchmarks, suggesting they may have a more robust architecture or training regime. Deepseek-1.5B consistently underperforms compared to other models, indicating potential limitations in its design or training data. The "pass@1" and "pass@10" metrics for AIME24 and AIME25 suggest that while the models may not always get the exact answer correct ("Score"), they often provide a correct answer within the top 1 or top 10 predictions. The data highlights the importance of benchmark-specific evaluations to understand the capabilities and limitations of different language models.