\n
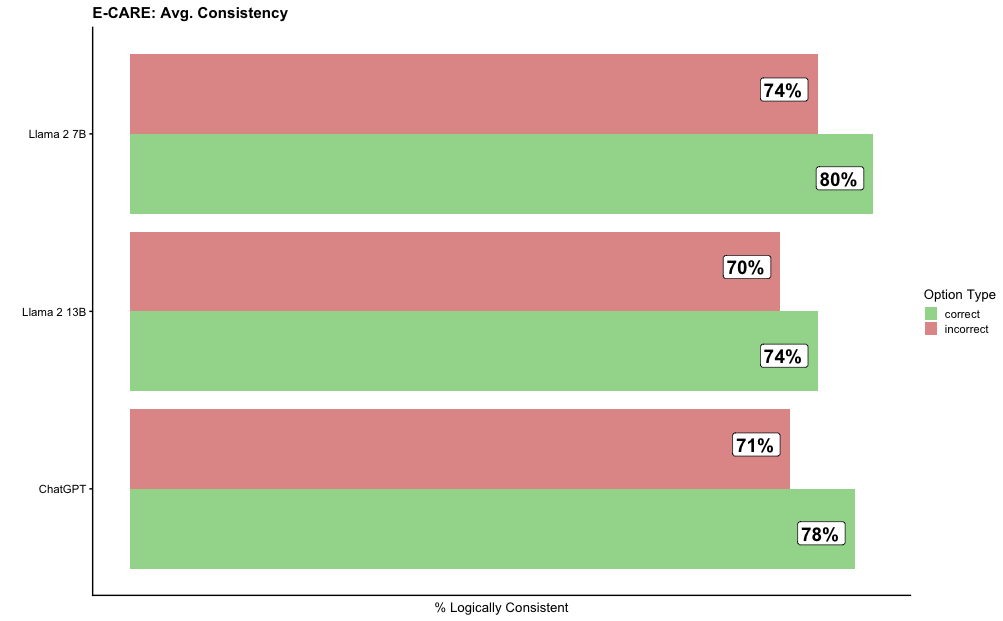
## Horizontal Bar Chart: E-CARE: Avg. Consistency
### Overview
This is a horizontal bar chart comparing the average logical consistency percentages of three large language models (LLMs) on the E-CARE benchmark. The chart evaluates each model's performance on "correct" versus "incorrect" option types.
### Components/Axes
* **Chart Title:** "E-CARE: Avg. Consistency" (located at the top-left).
* **Y-Axis (Vertical):** Lists the three models being compared. From top to bottom: "Llama 2 7B", "Llama 2 13B", "ChatGPT".
* **X-Axis (Horizontal):** Labeled "% Logically Consistent". The axis scale runs from 0 to 100, with major tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located on the right side of the chart, titled "Option Type". It defines two categories:
* A green square labeled "correct".
* A red (salmon/pinkish-red) square labeled "incorrect".
* **Data Bars:** For each model, there are two horizontal bars stacked vertically. The top bar for each model is red (incorrect), and the bottom bar is green (correct). Each bar has its exact percentage value annotated at its right end.
### Detailed Analysis
The chart presents the following specific data points, confirmed by cross-referencing bar color with the legend:
**1. Llama 2 7B (Topmost model group)**
* **Incorrect (Red Bar):** 74%
* **Correct (Green Bar):** 80%
* **Trend:** The green "correct" bar is longer than the red "incorrect" bar, indicating higher consistency for correct options.
**2. Llama 2 13B (Middle model group)**
* **Incorrect (Red Bar):** 70%
* **Correct (Green Bar):** 74%
* **Trend:** The green "correct" bar is longer than the red "incorrect" bar. Both values are lower than the corresponding values for Llama 2 7B.
**3. ChatGPT (Bottom model group)**
* **Incorrect (Red Bar):** 71%
* **Correct (Green Bar):** 78%
* **Trend:** The green "correct" bar is longer than the red "incorrect" bar. Its "correct" score is the second highest, and its "incorrect" score is the second lowest among the three models.
### Key Observations
* **Universal Pattern:** For all three models, the logical consistency score for "correct" options is higher than for "incorrect" options.
* **Highest Score:** Llama 2 7B achieves the highest single score on the chart: 80% consistency on correct options.
* **Lowest Score:** Llama 2 13B has the lowest score on the chart: 70% consistency on incorrect options.
* **Model Comparison:** Llama 2 7B outperforms Llama 2 13B on both metrics. ChatGPT's performance falls between the two Llama models on the "correct" metric but is closer to Llama 2 13B on the "incorrect" metric.
* **Consistency Gap:** The gap between "correct" and "incorrect" consistency is largest for ChatGPT (7 percentage points) and smallest for Llama 2 13B (4 percentage points).
### Interpretation
This chart from the E-CARE benchmark suggests a fundamental characteristic of the evaluated LLMs: they are more logically consistent when generating or evaluating correct answers compared to incorrect ones. This could imply that the models' reasoning processes are more robust or less prone to contradiction when aligned with factual or logically sound premises.
The data does not show a simple "bigger model is better" trend, as the smaller Llama 2 7B model outperforms the larger Llama 2 13B model on both measures. This could point to factors beyond parameter count, such as differences in training data, fine-tuning, or the specific nature of the E-CARE tasks. ChatGPT demonstrates strong but not leading performance, sitting between the two Llama variants. The relatively narrow range of scores (70% to 80%) indicates that all models achieve a moderately high level of logical consistency on this benchmark, but there is clear room for improvement, especially on handling incorrect options consistently.