## Bar Chart: E-CARE Avg. Consistency
### Overview
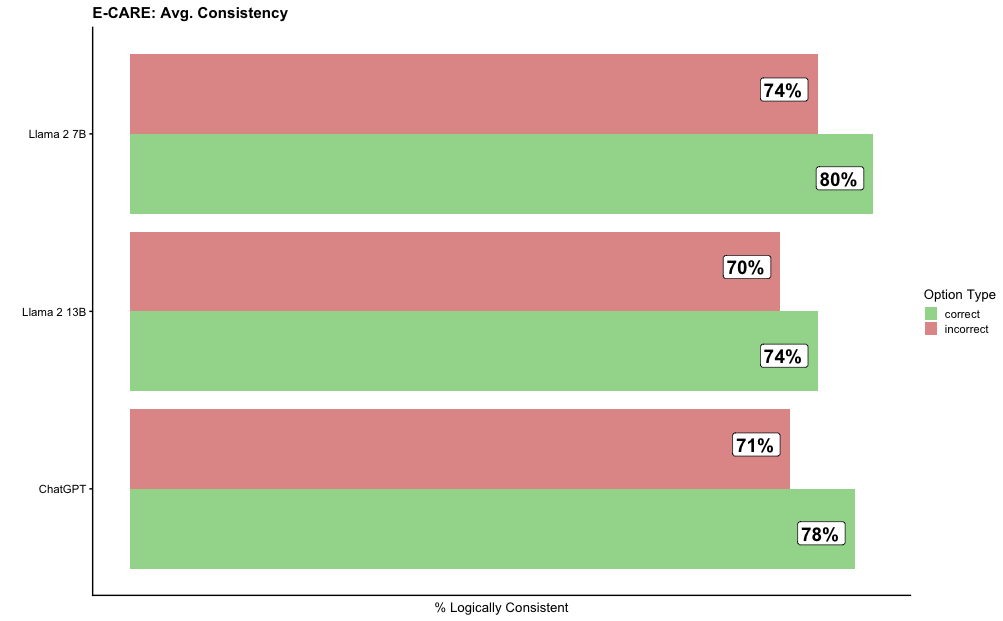
The chart compares the average logical consistency of three AI models (Llama 2 7B, Llama 2 13B, and ChatGPT) across two categories: "correct" and "incorrect" responses. Horizontal bars represent percentages, with green for "correct" and red for "incorrect."
### Components/Axes
- **X-axis**: "% Logically Consistent" (scale: 0% to 100%, labeled in increments of 10%).
- **Y-axis**: Model names (Llama 2 7B, Llama 2 13B, ChatGPT), ordered from top to bottom.
- **Legend**:
- Green: "correct" responses.
- Red: "incorrect" responses.
- **Text Embedded in Bars**: Percentages for each category (e.g., "80%", "74%").
### Detailed Analysis
1. **Llama 2 7B**:
- Correct: 80% (green bar).
- Incorrect: 74% (red bar).
2. **Llama 2 13B**:
- Correct: 74% (green bar).
- Incorrect: 70% (red bar).
3. **ChatGPT**:
- Correct: 78% (green bar).
- Incorrect: 71% (red bar).
### Key Observations
- **Llama 2 7B** has the highest consistency in both "correct" (80%) and "incorrect" (74%) responses, with the smallest gap (6%) between the two categories.
- **Llama 2 13B** shows the lowest "correct" consistency (74%) but also the lowest "incorrect" consistency (70%), with a 4% gap.
- **ChatGPT** has the most balanced performance, with a 7% gap between "correct" (78%) and "incorrect" (71%).
### Interpretation
The data suggests that **Llama 2 7B** is the most consistent overall, though its "correct" and "incorrect" responses are closely matched. **Llama 2 13B** exhibits lower consistency in both categories but with a narrower gap, potentially indicating more polarized performance. **ChatGPT** demonstrates higher accuracy in "correct" responses but slightly lower consistency in "incorrect" responses compared to Llama 2 models. The chart highlights trade-offs between accuracy and consistency across models, with Llama 2 7B prioritizing consistency over accuracy and ChatGPT leaning toward higher correctness.