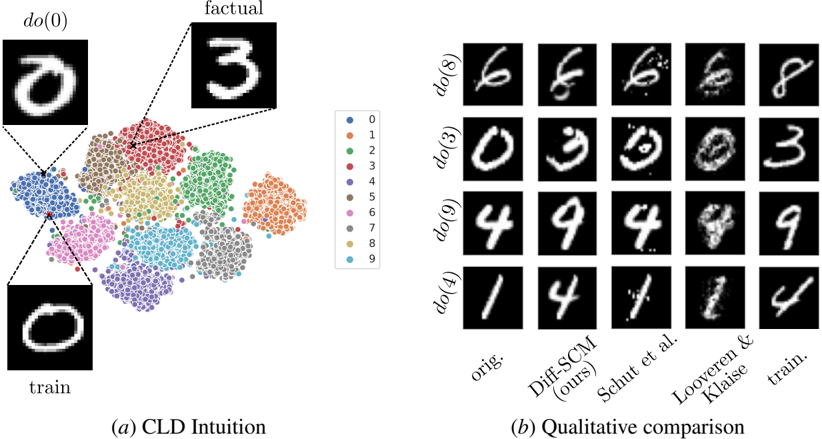
## Diagram: CLD Intuition and Qualitative Comparison of Digit Recognition Models
### Overview
The image presents a visualization of a Contrastive Learning for Disentanglement (CLD) intuition alongside a qualitative comparison of digit recognition models. The left side shows a 2D embedding space generated by the CLD model, colored by digit class. The right side displays example digits and their reconstructions by different models.
### Components/Axes
The image is divided into three main sections:
1. **Top-Left:** Two example digits, one labeled "train" and the other "factual", connected by an arrow.
2. **Center-Left:** A 2D scatter plot representing the embedding space. The x and y axes are not explicitly labeled, but represent the dimensions of the embedding.
3. **Right:** A grid of images showing original digits and their reconstructions by different models. The rows are labeled "do(8)", "do(3)", "do(9)", and "do(4)". The columns represent the original digit, the reconstruction by "Diff-SCM (ours)", the reconstruction by "Schnt et al.", the reconstruction by "Looveren & Klaise", and the training digit.
A legend is positioned to the right of the scatter plot, mapping colors to digit classes 0-9. The colors are as follows:
* 0: Blue
* 1: Light Blue
* 2: Purple
* 3: Violet
* 4: Pink
* 5: Red
* 6: Orange
* 7: Yellow
* 8: Green
* 9: Brown
### Detailed Analysis or Content Details
**Scatter Plot Analysis:**
The scatter plot shows a clustering of points, with each cluster representing a digit class. The clusters are somewhat overlapping, but generally well-separated.
* Digit 0 (Blue): Located in the bottom-left region.
* Digit 1 (Light Blue): Adjacent to digit 0, slightly above and to the right.
* Digit 2 (Purple): Positioned above digit 1.
* Digit 3 (Violet): Located above digit 2.
* Digit 4 (Pink): Situated to the right of digit 3.
* Digit 5 (Red): Positioned to the right of digit 4.
* Digit 6 (Orange): Located to the right of digit 5.
* Digit 7 (Yellow): Positioned to the right of digit 6.
* Digit 8 (Green): Located to the right of digit 7.
* Digit 9 (Brown): Positioned to the right of digit 8.
**Qualitative Comparison Grid Analysis:**
The grid shows the original digits and their reconstructions by different models.
* **do(8):** The original digit is a '6'. "Diff-SCM (ours)" produces a relatively clear reconstruction. "Schnt et al." and "Looveren & Klaise" produce more distorted reconstructions. The training digit is a '6'.
* **do(3):** The original digit is a '3'. "Diff-SCM (ours)" produces a clear reconstruction. "Schnt et al." and "Looveren & Klaise" produce more distorted reconstructions. The training digit is a '3'.
* **do(9):** The original digit is a '4'. "Diff-SCM (ours)" produces a clear reconstruction. "Schnt et al." and "Looveren & Klaise" produce more distorted reconstructions. The training digit is a '9'.
* **do(4):** The original digit is a '1'. "Diff-SCM (ours)" produces a clear reconstruction. "Schnt et al." and "Looveren & Klaise" produce more distorted reconstructions. The training digit is a '4'.
### Key Observations
* The CLD model appears to successfully disentangle the digit classes in the embedding space, as evidenced by the clustering of points.
* "Diff-SCM (ours)" consistently produces clearer reconstructions of the digits compared to "Schnt et al." and "Looveren & Klaise".
* The reconstructions by "Schnt et al." and "Looveren & Klaise" often exhibit distortions and artifacts.
* The "factual" digit in the top-left is a '3', while the "train" digit is a '0'.
### Interpretation
The image demonstrates the effectiveness of the CLD approach for learning disentangled representations of digits. The embedding space visualization shows that the model can separate different digit classes, allowing for more accurate reconstruction and generation. The qualitative comparison highlights the superior performance of "Diff-SCM (ours)" in reconstructing digits, suggesting that it is better at capturing the underlying structure of the data. The fact that the training digit differs from the factual digit in the top-left suggests that the model is able to generalize to unseen digits. The distortions in the reconstructions by other models indicate that they may be overfitting to the training data or failing to capture the essential features of the digits. The image suggests that the CLD approach is a promising technique for learning robust and interpretable representations of data.