TECHNICAL ASSET FINGERPRINT
727385ee50267584f3592dfc
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
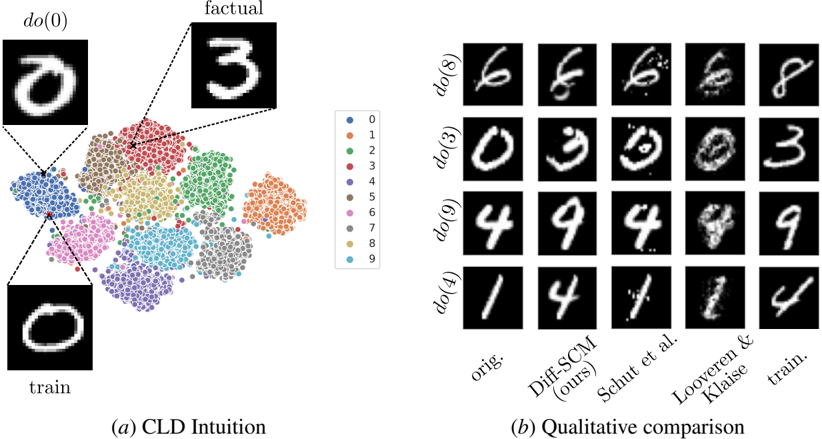
## [Composite Technical Figure]: Causal Latent Diffusion (CLD) Intuition and Qualitative Comparison
### Overview
The image is a two-part technical figure from a research paper, likely in the field of machine learning or causal inference. It visually explains a method called "CLD" (Causal Latent Diffusion) and provides a qualitative comparison of its performance against other methods on a handwritten digit dataset (presumably MNIST). Part (a) illustrates the conceptual intuition behind the method using a scatter plot and example images. Part (b) presents a grid of generated images to compare the results of different techniques.
### Components/Axes
**Part (a): CLD Intuition**
* **Central Element:** A scatter plot (likely a t-SNE or UMAP projection) showing clusters of data points.
* **Legend:** Positioned to the right of the scatter plot. It is a vertical list mapping colors to digit classes:
* Blue dot: 0
* Orange dot: 1
* Green dot: 2
* Red dot: 3
* Purple dot: 4
* Brown dot: 5
* Pink dot: 6
* Gray dot: 7
* Olive dot: 8
* Cyan dot: 9
* **Annotated Images:** Three example handwritten digit images are connected to the scatter plot via dashed lines:
* **Top-Left:** Labeled `do(0)`. Shows a white digit "0" on a black background. A dashed line connects it to a point within the blue cluster (digit 0).
* **Top-Right:** Labeled `factual`. Shows a white digit "3" on a black background. A dashed line connects it to a point within the red cluster (digit 3).
* **Bottom-Left:** Labeled `train`. Shows a white digit "0" on a black background. A dashed line connects it to a different point within the blue cluster (digit 0).
* **Caption:** `(a) CLD Intuition` is centered below this section.
**Part (b): Qualitative Comparison**
* **Structure:** A 4-row by 5-column grid of small grayscale images.
* **Row Labels (Left Side):** Each row is labeled with a causal intervention command:
* Row 1: `do(8)`
* Row 2: `do(3)`
* Row 3: `do(9)`
* Row 4: `do(4)`
* **Column Labels (Bottom):** Each column is labeled with a method or data source:
* Column 1: `orig.` (Original)
* Column 2: `Diff-SCM (ours)` (The authors' proposed method)
* Column 3: `Schut et al.` (A competing method)
* Column 4: `Looveren & Klaise` (Another competing method)
* Column 5: `train.` (Training data sample)
* **Caption:** `(b) Qualitative comparison` is centered below this section.
### Detailed Analysis
**Part (a) Analysis:**
* The scatter plot shows distinct, non-overlapping clusters for each digit class (0-9), indicating that the model's latent space effectively separates different digits.
* The `do(0)` and `train` images are both examples of the digit 0, connected to the same blue cluster, but to different specific points within it. This suggests they are different samples from the same class.
* The `factual` image (digit 3) is connected to the red cluster, demonstrating the link between a specific data point and its class cluster in the latent space.
**Part (b) Analysis - Row by Row Trend Verification:**
* **Row `do(8)`:** The `orig.` image is a clear "8". The `Diff-SCM (ours)` output is a slightly noisier but recognizable "8". `Schut et al.` produces a very noisy, distorted "8". `Looveren & Klaise` generates a blurry, less distinct "8". The `train.` sample is a clear "8".
* **Row `do(3)`:** The `orig.` is a clear "3". `Diff-SCM (ours)` produces a clear "3". `Schut et al.` generates a noisy "3" with artifacts. `Looveren & Klaise` produces a very noisy, almost unrecognizable "3". The `train.` sample is a clear "3".
* **Row `do(9)`:** The `orig.` is a clear "9". `Diff-SCM (ours)` produces a clear "9". `Schut et al.` generates a very noisy, fragmented "9". `Looveren & Klaise` produces a noisy "9" with a disconnected loop. The `train.` sample is a clear "9".
* **Row `do(4)`:** The `orig.` is a clear "4". `Diff-SCM (ours)` produces a clear "4". `Schut et al.` generates a noisy "4". `Looveren & Klaise` produces a very noisy, distorted "4". The `train.` sample is a clear "4".
**General Trend in (b):** Across all rows, the `Diff-SCM (ours)` column consistently produces digit images that are the clearest and most faithful to the `orig.` and `train.` examples among the three methods compared. The methods by `Schut et al.` and `Looveren & Klaise` consistently introduce significant noise, blurriness, or structural distortions.
### Key Observations
1. **Method Superiority:** The proposed `Diff-SCM` method visually outperforms the two baseline methods (`Schut et al.` and `Looveren & Klaise`) in generating clean, recognizable digits after a causal intervention (`do`-operation).
2. **Latent Space Structure:** Part (a) confirms that the model has learned a well-structured latent space where digits of the same class are grouped together.
3. **Intervention Consistency:** The `do` operation appears to successfully target a specific digit class, as all outputs in a given row of part (b) attempt to generate that digit, albeit with varying success.
4. **Noise Profiles:** The failure modes of the baseline methods are distinct: `Schut et al.` tends to produce high-frequency noise and speckles, while `Looveren & Klaise` often results in blurriness and loss of structural integrity.
### Interpretation
This figure serves a dual purpose in a research context. **First**, part (a) provides an intuitive, visual explanation of the core concept: the model operates on a latent space where data points (digits) are clustered by class, and causal interventions (`do`-operations) can be performed on these points. The dashed lines explicitly map concrete image examples to their abstract positions in this latent space, bridging the gap between data and model representation.
**Second**, part (b) acts as empirical, qualitative evidence for the method's effectiveness. By placing its results side-by-side with established baselines and the ground truth (`orig.`, `train.`), the authors demonstrate that their method generates higher-fidelity images. This is crucial for tasks like counterfactual image generation or algorithmic fairness, where producing realistic and accurate modifications is essential. The clear visual superiority of `Diff-SCM` suggests it better preserves the underlying data distribution while successfully applying the desired causal intervention, making it a more reliable tool for causal reasoning in image domains. The figure effectively argues that the proposed method's approach to modeling causality in latent space yields tangible, visible improvements in output quality.
DECODING INTELLIGENCE...