# Technical Document Extraction: Attention Forward Speed Benchmark
## 1. Document Metadata
* **Title:** Attention forward speed, head dim 256 (H100 80GB SXM5)
* **Image Type:** Grouped Bar Chart
* **Primary Language:** English
## 2. Component Isolation
### Header
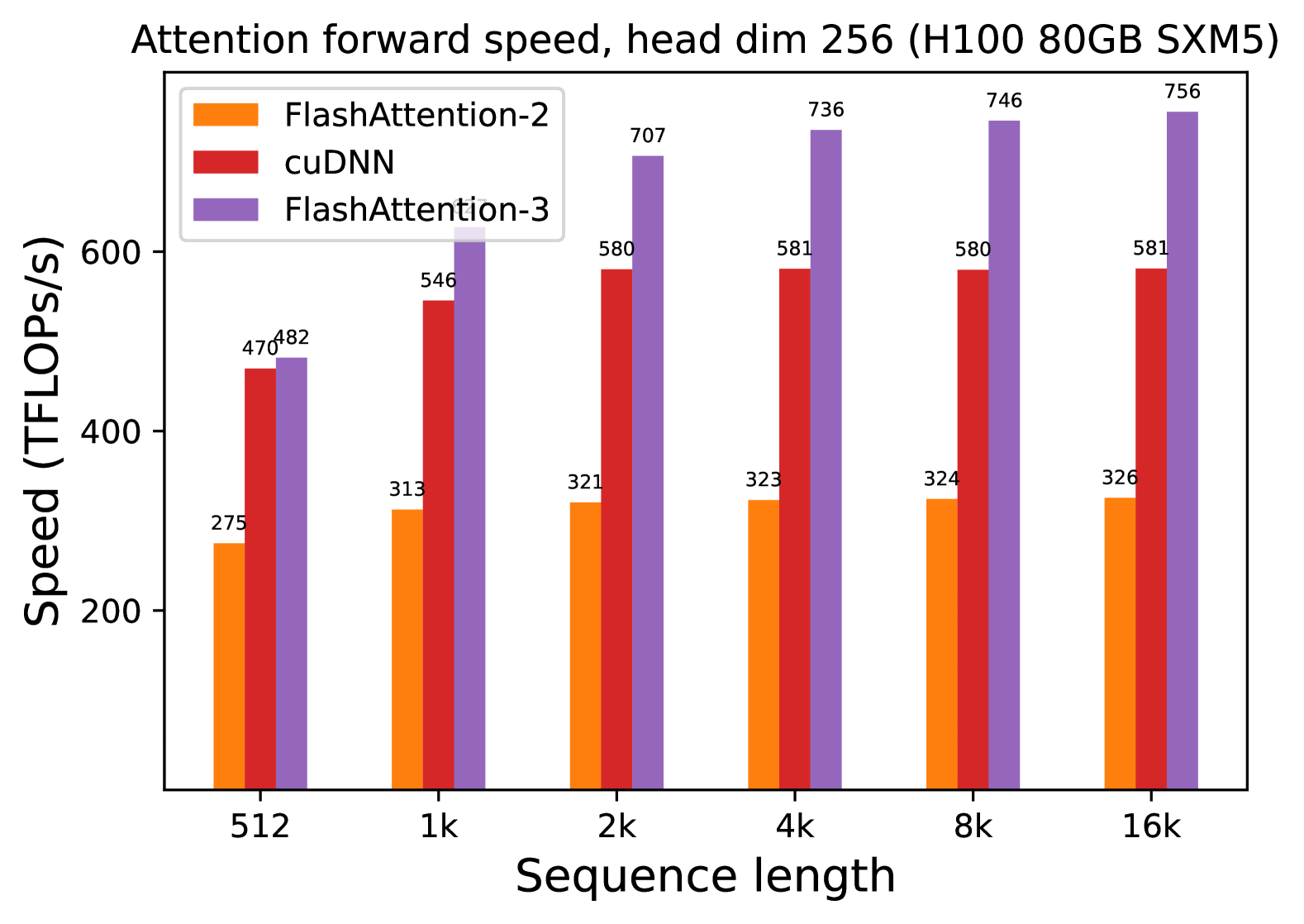
* **Main Title:** "Attention forward speed, head dim 256 (H100 80GB SXM5)"
* **Context:** This chart benchmarks the performance of different attention mechanisms on an NVIDIA H100 80GB SXM5 GPU, specifically for a head dimension of 256.
### Main Chart Area
* **Y-Axis Label:** Speed (TFLOPs/s)
* **Y-Axis Scale:** Linear, ranging from 200 to 600+ (markers at 200, 400, 600).
* **X-Axis Label:** Sequence length
* **X-Axis Categories:** 512, 1k, 2k, 4k, 8k, 16k.
* **Legend (Top-Left):**
* **Orange:** FlashAttention-2
* **Red:** cuDNN
* **Purple:** FlashAttention-3
### Footer
* No footer text present.
## 3. Data Extraction and Trend Analysis
### Trend Verification
1. **FlashAttention-2 (Orange):** Shows a slight upward trend from 512 to 2k, then plateaus/stabilizes between 321 and 326 TFLOPs/s for higher sequence lengths.
2. **cuDNN (Red):** Shows a significant jump from 512 to 2k, then plateaus almost perfectly at 580-581 TFLOPs/s from 2k through 16k.
3. **FlashAttention-3 (Purple):** Shows the most aggressive upward trend, starting slightly above cuDNN at 512 and scaling significantly until it plateaus/stabilizes around 736-756 TFLOPs/s at higher sequence lengths.
### Data Table (Reconstructed)
The following table represents the precise numerical values labeled above each bar in the chart.
| Sequence Length | FlashAttention-2 (Orange) | cuDNN (Red) | FlashAttention-3 (Purple) |
| :--- | :--- | :--- | :--- |
| **512** | 275 | 470 | 482 |
| **1k** | 313 | 546 | 639 |
| **2k** | 321 | 580 | 707 |
| **4k** | 323 | 581 | 736 |
| **8k** | 324 | 580 | 746 |
| **16k** | 326 | 581 | 756 |
## 4. Technical Summary
The chart demonstrates a clear performance hierarchy for attention forward passes on H100 hardware with a head dimension of 256.
* **FlashAttention-3** is the highest-performing implementation, reaching a peak of **756 TFLOPs/s** at a 16k sequence length. It significantly outperforms both cuDNN and FlashAttention-2 across all tested sequence lengths.
* **cuDNN** maintains a middle-ground performance, stabilizing at approximately **581 TFLOPs/s**.
* **FlashAttention-2** is the slowest of the three in this specific configuration, stabilizing at approximately **326 TFLOPs/s**.
* **Scaling:** All three methods show performance gains as sequence length increases from 512 to 2k, after which performance gains become marginal (plateauing), suggesting the GPU reaches maximum utilization for these kernels at these sequence lengths.