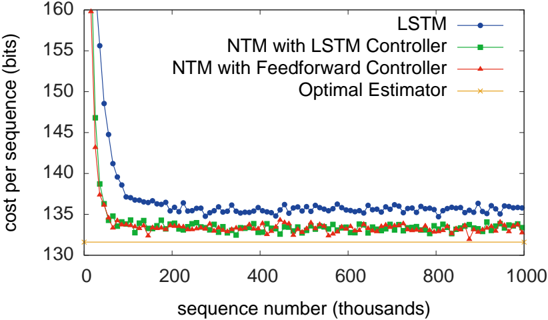
## Line Chart: Model Cost per Sequence vs. Training Progress
### Overview
The image is a line chart comparing the performance of four different models or estimators over the course of training. Performance is measured as "cost per sequence" in bits, plotted against the number of training sequences processed (in thousands). The chart demonstrates the learning curves and final convergence points of the models.
### Components/Axes
* **Chart Type:** Line chart with multiple series.
* **Y-Axis (Vertical):**
* **Label:** `cost per sequence (bits)`
* **Scale:** Linear, ranging from 130 to 160.
* **Major Ticks:** 130, 135, 140, 145, 150, 155, 160.
* **X-Axis (Horizontal):**
* **Label:** `sequence number (thousands)`
* **Scale:** Linear, ranging from 0 to 1000.
* **Major Ticks:** 0, 200, 400, 600, 800, 1000.
* **Legend (Position: Top-right corner, inside the plot area):**
* **LSTM:** Blue line with circular markers.
* **NTM with LSTM Controller:** Green line with square markers.
* **NTM with Feedforward Controller:** Red line with triangular markers.
* **Optimal Estimator:** Orange line with 'x' markers.
### Detailed Analysis
**1. LSTM (Blue line, circles):**
* **Trend:** Starts at the highest cost (~160 bits at sequence 0), experiences a very steep decline within the first ~50k sequences, then continues a slower, noisy descent before stabilizing.
* **Data Points (Approximate):**
* Start (0k): ~160 bits
* 50k: ~148 bits
* 100k: ~137 bits
* 200k: ~136 bits
* 400k: ~135.5 bits
* 600k: ~135.5 bits
* 800k: ~135.5 bits
* 1000k: ~135.5 bits
* **Final Plateau:** Stabilizes around 135-136 bits.
**2. NTM with LSTM Controller (Green line, squares):**
* **Trend:** Starts at a lower cost than LSTM (~147 bits), drops rapidly, and converges to a lower final cost. The curve is smoother than the LSTM's after the initial drop.
* **Data Points (Approximate):**
* Start (0k): ~147 bits
* 50k: ~135 bits
* 100k: ~134 bits
* 200k: ~133.5 bits
* 400k: ~133.5 bits
* 600k: ~133.5 bits
* 800k: ~133.5 bits
* 1000k: ~133.5 bits
* **Final Plateau:** Stabilizes around 133-134 bits.
**3. NTM with Feedforward Controller (Red line, triangles):**
* **Trend:** Starts at a similar point to the NTM-LSTM (~143 bits), drops quickly, and achieves the lowest final cost among the learning models, very close to the optimal estimator.
* **Data Points (Approximate):**
* Start (0k): ~143 bits
* 50k: ~134 bits
* 100k: ~133 bits
* 200k: ~132.5 bits
* 400k: ~132.5 bits
* 600k: ~132.5 bits
* 800k: ~132.5 bits
* 1000k: ~132.5 bits
* **Final Plateau:** Stabilizes around 132-133 bits.
**4. Optimal Estimator (Orange line, 'x's):**
* **Trend:** A perfectly flat, horizontal line, indicating a constant, non-learning benchmark.
* **Data Point:** Constant at ~132 bits across the entire x-axis.
### Key Observations
1. **Learning Speed:** All three learning models (LSTM, NTM-LSTM, NTM-FF) show a dramatic reduction in cost within the first 50,000-100,000 sequences, indicating rapid initial learning.
2. **Performance Hierarchy:** A clear and consistent performance hierarchy is established early and maintained: NTM with Feedforward Controller (best) > NTM with LSTM Controller > LSTM (worst of the learning models).
3. **Convergence:** All learning models converge to a stable cost value well before 400,000 sequences. Further training (up to 1,000,000 sequences) yields negligible improvement.
4. **Proximity to Optimal:** The NTM models, particularly the one with a Feedforward Controller, converge to a cost very close to the theoretical "Optimal Estimator" line (~132 bits), suggesting near-optimal performance on this task. The LSTM model converges to a noticeably higher cost (~135.5 bits).
5. **Noise:** The LSTM curve exhibits more variance (noise) in its cost after convergence compared to the smoother NTM curves.
### Interpretation
This chart is a performance benchmark likely from a machine learning paper on neural memory models. It demonstrates the superiority of Neural Turing Machines (NTMs) over a standard LSTM on a specific sequential task, measured by bits per sequence (a common metric in compression or prediction tasks).
* **What the data suggests:** The NTM architecture, which augments a neural network with an external memory matrix, learns a more efficient representation or algorithm for the task than the LSTM alone. The choice of controller within the NTM matters, with the simpler Feedforward Controller slightly outperforming the more complex LSTM Controller in this instance.
* **Relationship between elements:** The "Optimal Estimator" line serves as a ground-truth baseline, representing the best possible performance (likely the entropy of the data-generating process). The learning curves show how quickly and effectively each model approaches this theoretical limit. The gap between a model's plateau and the optimal line represents its residual inefficiency.
* **Notable anomalies/trends:** The most significant trend is the clear stratification of model performance. The fact that both NTM variants outperform the LSTM supports the hypothesis that explicit memory access is beneficial for this task. The Feedforward Controller's slight edge might indicate that for this specific problem, the recurrent dynamics of an LSTM controller are unnecessary or even slightly detrimental. The rapid convergence suggests the task is learnable, and the models quickly find a stable, near-optimal solution.