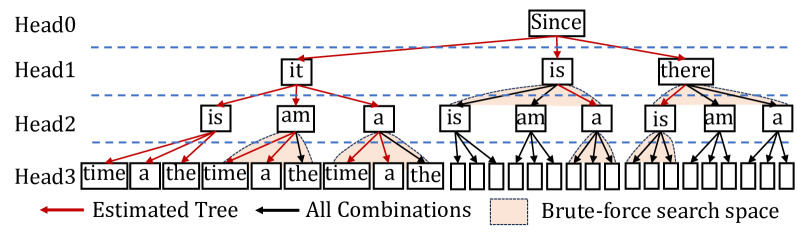
\n
## Diagram: Parsing Tree Visualization
### Overview
The image depicts a parsing tree structure used in natural language processing, specifically illustrating a method for estimating a tree compared to a brute-force search space. The tree represents the possible syntactic structures for a sentence, starting from the root node "Since" and branching down to individual words. The diagram highlights the estimated tree in red and the full search space in light orange.
### Components/Axes
The diagram is organized into four horizontal levels labeled "Head0", "Head1", "Head2", and "Head3". These represent different levels of syntactic abstraction.
- **Head0:** Contains the root node "Since".
- **Head1:** Contains the words "it", "is", and "there".
- **Head2:** Contains the words "is", "am", "a" repeated multiple times.
- **Head3:** Contains the words "time", "the", "time", "the", and a series of empty rectangles.
The diagram also includes the following visual elements:
- **Red Arrows:** Indicate the "Estimated Tree" path.
- **Black Arrows:** Indicate "All Combinations" paths.
- **Light Orange Rectangles:** Represent the "Brute-force search space".
- **Dashed Blue Lines:** Separate the Head levels.
### Detailed Analysis or Content Details
The tree structure begins with "Since" at Head0. From "Since", three branches extend to Head1:
1. "it"
2. "is"
3. "there"
From "it", branches extend to Head2:
1. "is"
2. "am"
3. "a"
From "is", branches extend to Head3:
1. "time"
2. "the time"
3. "a"
From "am", branches extend to Head3:
1. "the time"
From "a", branches extend to Head3:
1. "the"
The remaining nodes at Head2 ("is", "am", "a" repeated) and Head3 are represented by empty rectangles, indicating a larger search space that is not part of the estimated tree. The number of empty rectangles at Head3 increases as the tree branches out.
### Key Observations
- The estimated tree (red arrows) represents a significantly smaller subset of the total possible combinations (black arrows).
- The brute-force search space (light orange rectangles) is much larger than the estimated tree, indicating the efficiency gain of the estimation method.
- The tree structure demonstrates a hierarchical decomposition of the sentence, starting from the root and branching down to individual words.
- The diagram visually emphasizes the trade-off between accuracy and computational cost in parsing.
### Interpretation
This diagram illustrates a method for parsing natural language sentences by estimating a likely syntactic structure rather than exhaustively searching all possible combinations. The "Estimated Tree" represents a heuristic approach to reduce the computational complexity of parsing, while the "Brute-force search space" highlights the exponential growth of possibilities as the sentence length increases. The use of different colors and arrow types effectively conveys the relationship between the estimated tree and the full search space. The diagram suggests that the estimation method provides a practical solution for parsing complex sentences by focusing on the most probable syntactic structures. The empty rectangles at Head3 indicate that the model does not consider all possible word combinations, which could potentially lead to errors but also significantly improves efficiency. The diagram is a visual representation of a core concept in natural language processing: the trade-off between accuracy and computational cost in parsing.