## Bar Chart: GPT-4 Accuracy by Presentation Style
### Overview
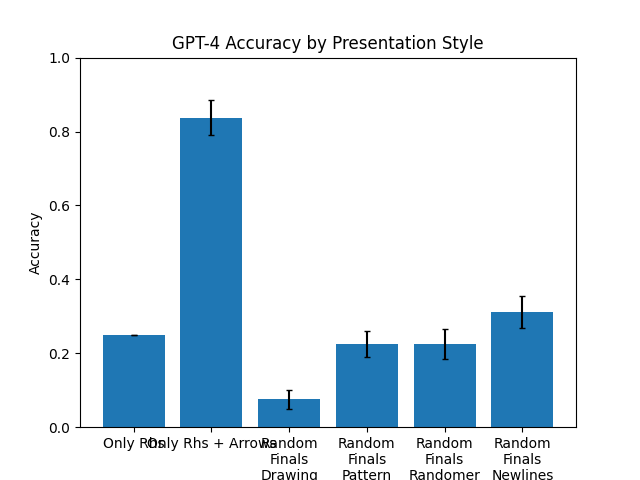
The chart compares the accuracy of GPT-4 across six presentation styles, with error bars indicating variability. The y-axis represents accuracy (0.0–1.0), and the x-axis lists presentation styles. All bars are blue, with no additional legend elements beyond the color coding.
### Components/Axes
- **Title**: "GPT-4 Accuracy by Presentation Style" (top-center).
- **X-Axis**: Labeled "Presentation Style" with categories:
- "Only Rows"
- "Rows + Arrows"
- "Random Finals Drawing"
- "Random Finals Pattern"
- "Random Finals Randomer"
- "Random Finals Newlines"
- **Y-Axis**: Labeled "Accuracy" (0.0–1.0 in increments of 0.2).
- **Legend**: Not explicitly visible; all bars use a single blue color.
### Detailed Analysis
1. **"Rows + Arrows"**: Tallest bar at ~0.83 accuracy (error bar ±0.05).
2. **"Only Rows"**: ~0.25 accuracy (error bar ±0.03).
3. **"Random Finals Drawing"**: ~0.07 accuracy (error bar ±0.02).
4. **"Random Finals Pattern"**: ~0.22 accuracy (error bar ±0.03).
5. **"Random Finals Randomer"**: ~0.22 accuracy (error bar ±0.03).
6. **"Random Finals Newlines"**: ~0.31 accuracy (error bar ±0.04).
### Key Observations
- "Rows + Arrows" achieves the highest accuracy (~83%), significantly outperforming all other styles.
- Random presentation styles cluster between ~7% and ~31% accuracy, with "Newlines" being the most effective among them.
- Error bars suggest moderate variability, particularly for "Rows + Arrows" (±5%) and "Newlines" (±4%).
### Interpretation
The data demonstrates that structured presentation styles (e.g., "Rows + Arrows") drastically improve GPT-4's accuracy compared to random configurations. The inclusion of arrows in rows correlates with the highest performance, suggesting that explicit visual cues enhance model interpretation. Random styles show minimal accuracy, with "Newlines" as a potential outlier due to its slightly higher performance (~31%). The error bars indicate that while "Rows + Arrows" has the largest variability, its mean accuracy remains robust. This implies that presentation style is a critical factor in optimizing GPT-4's output reliability.