## Diagram: Logical Fallacy Understanding Dataset (LFUD) Creation and Application
### Overview
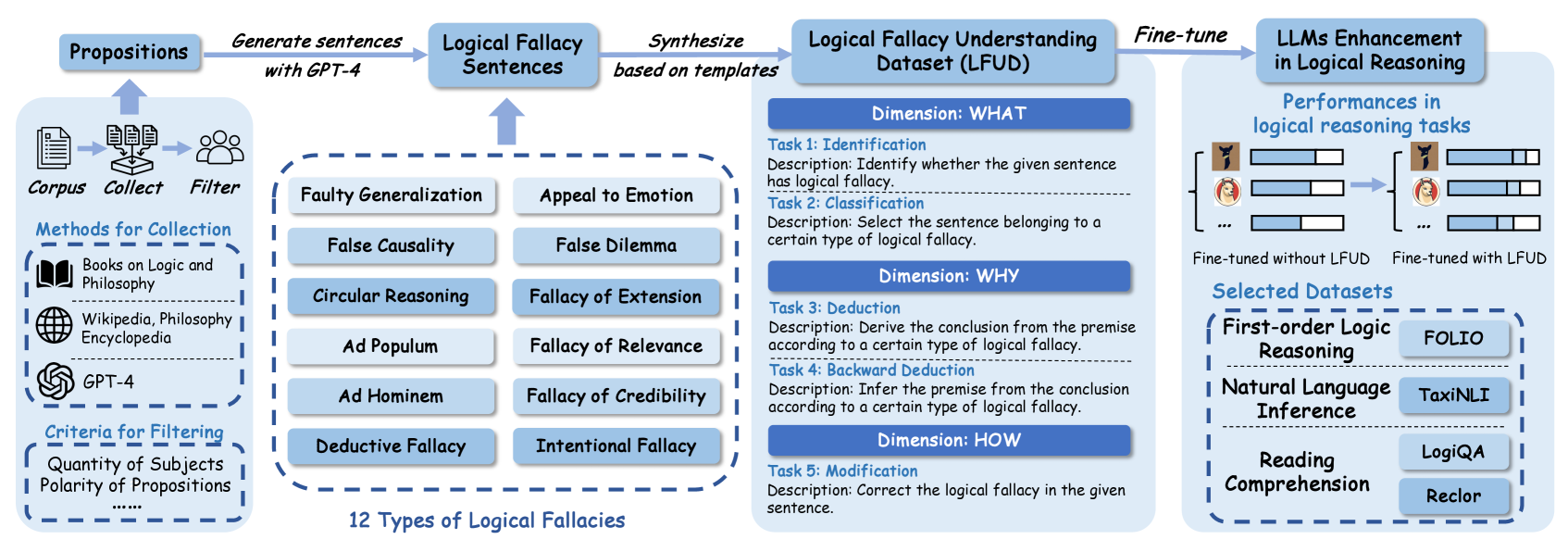
The image is a diagram illustrating the process of creating a Logical Fallacy Understanding Dataset (LFUD) and its application in enhancing Large Language Models (LLMs) for logical reasoning. It outlines the data collection, synthesis, and fine-tuning stages, along with performance evaluation and selected datasets.
### Components/Axes
* **Propositions:** Starting point for generating sentences.
* **Corpus:** Collection of text data.
* Methods for Collection:
* Books on Logic and Philosophy
* Wikipedia, Philosophy Encyclopedia
* GPT-4
* Criteria for Filtering:
* Quantity of Subjects
* Polarity of Propositions
* **Logical Fallacy Sentences:** Sentences containing logical fallacies.
* **Logical Fallacy Understanding Dataset (LFUD):** Dataset created for training LLMs.
* Dimensions:
* WHAT:
* Task 1: Identification - Identify whether the given sentence has logical fallacy.
* Task 2: Classification - Select the sentence belonging to a certain type of logical fallacy.
* WHY:
* Task 3: Deduction - Derive the conclusion from the premise according to a certain type of logical fallacy.
* Task 4: Backward Deduction - Infer the premise from the conclusion according to a certain type of logical fallacy.
* HOW:
* Task 5: Modification - Correct the logical fallacy in the given sentence.
* **LLMs Enhancement in Logical Reasoning:** Application of LFUD to improve LLMs.
* **Selected Datasets:** Datasets used for evaluation.
* First-order Logic Reasoning: FOLIO
* Natural Language Inference: TaxiNLI
* Reading Comprehension: LogiQA, Reclor
* **12 Types of Logical Fallacies:**
* Faulty Generalization
* False Causality
* Circular Reasoning
* Ad Populum
* Ad Hominem
* Deductive Fallacy
* Appeal to Emotion
* False Dilemma
* Fallacy of Extension
* Fallacy of Relevance
* Fallacy of Credibility
* Intentional Fallacy
### Detailed Analysis or ### Content Details
1. **Data Collection:**
* Propositions are used to generate sentences with GPT-4.
* A corpus is collected and filtered. The corpus consists of books on logic and philosophy, Wikipedia, philosophy encyclopedia, and GPT-4 generated text.
* Filtering criteria include the quantity of subjects and the polarity of propositions.
2. **Logical Fallacy Sentence Generation:**
* Logical fallacy sentences are synthesized based on templates.
3. **LFUD Creation:**
* The LFUD is structured around three dimensions: WHAT, WHY, and HOW.
* WHAT: Focuses on identifying and classifying logical fallacies.
* WHY: Focuses on deduction and backward deduction related to logical fallacies.
* HOW: Focuses on modifying sentences to correct logical fallacies.
4. **LLM Fine-tuning and Evaluation:**
* The LFUD is used to fine-tune LLMs.
* The performance of LLMs in logical reasoning tasks is evaluated.
* The diagram shows a comparison of performance "Fine-tuned without LFUD" vs "Fine-tuned with LFUD", with the latter showing improved performance.
* Selected datasets for evaluation include FOLIO, TaxiNLI, LogiQA, and Reclor.
5. **Performances in logical reasoning tasks:**
* The diagram shows performance bars for LLMs fine-tuned without LFUD and with LFUD.
* The performance bars for "Fine-tuned with LFUD" are longer than those for "Fine-tuned without LFUD", indicating improved performance.
### Key Observations
* The diagram provides a clear overview of the LFUD creation and application process.
* The use of GPT-4 in generating sentences and the structured approach to LFUD creation are notable.
* The performance comparison highlights the effectiveness of LFUD in enhancing LLMs for logical reasoning.
### Interpretation
The diagram illustrates a systematic approach to improving LLMs' logical reasoning capabilities. By creating a dedicated dataset (LFUD) focused on logical fallacies, the fine-tuned LLMs demonstrate enhanced performance in logical reasoning tasks. The process involves data collection from diverse sources, synthesis of logical fallacy sentences, and a structured approach to training the LLMs. The performance comparison between LLMs fine-tuned with and without LFUD underscores the value of this approach. The diagram suggests that targeted datasets, like LFUD, can significantly improve the performance of LLMs in specific domains.
The presence of "自動車" is not relevant to the diagram and appears to be an OCR error.