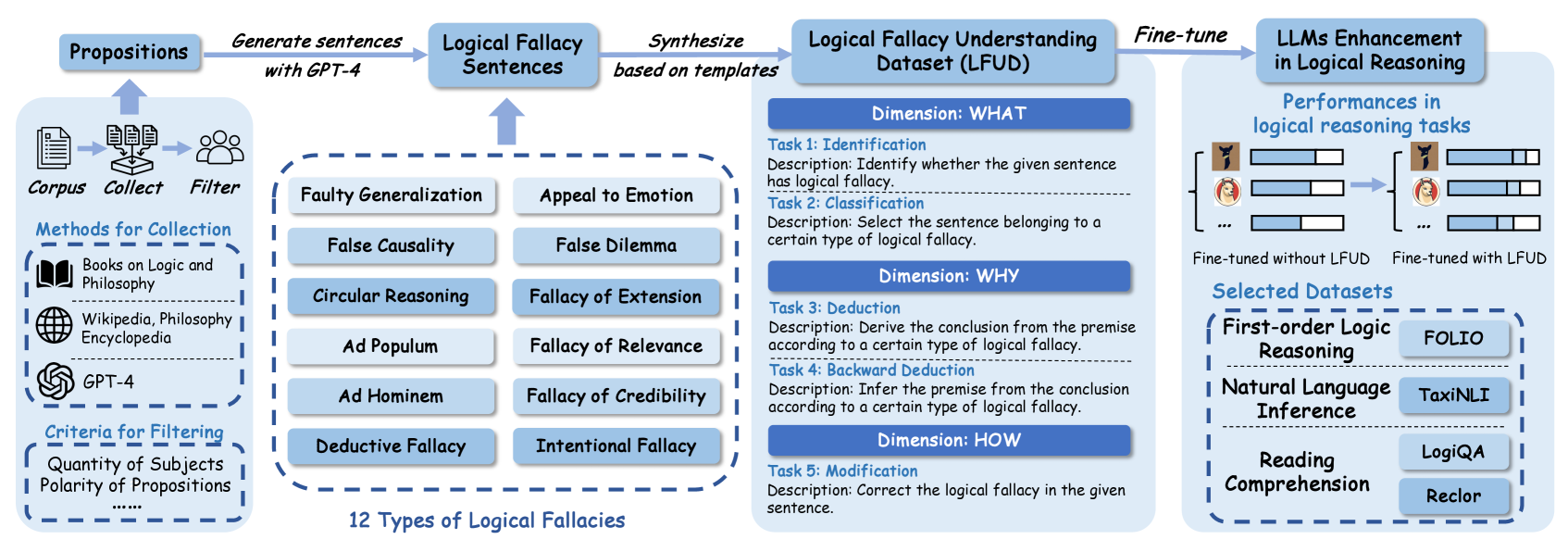
## Diagram: LLMs Enhancement in Logical Reasoning Pipeline
### Overview
This diagram illustrates a pipeline for enhancing Large Language Models (LLMs) in logical reasoning. The pipeline begins with proposition generation, proceeds through logical fallacy sentence creation and dataset synthesis, then fine-tuning, and finally evaluates performance improvements. The diagram highlights the types of logical fallacies considered and the datasets used for evaluation.
### Components/Axes
The diagram is structured horizontally, with distinct stages flowing from left to right. Key components include:
* **Propositions:** Initial stage involving corpus collection, filtering, and generation of sentences using GPT-4.
* **Logical Fallacy Sentences:** Creation of sentences exhibiting logical fallacies.
* **Logical Fallacy Understanding Dataset (LFUD):** A synthesized dataset based on templates.
* **Fine-tune:** The process of fine-tuning LLMs using the LFUD.
* **LLMs Enhancement in Logical Reasoning:** Evaluation of performance improvements.
* **Dimension: WHAT:** Focuses on identification and classification of logical fallacies.
* **Dimension: WHY:** Focuses on deduction and backward deduction.
* **Dimension: HOW:** Focuses on modification of logical fallacies.
* **Selected Datasets:** Lists datasets used for evaluation, categorized by reasoning type.
### Detailed Analysis or Content Details
**1. Propositions (Leftmost Section):**
* **Corpus:** Collection from "Books on Logic and Philosophy" and "Wikipedia, Philosophy Encyclopedia".
* **Filter:** Criteria for filtering include "Quantity of Subjects" and "Polarity of Propositions".
* **GPT-4:** Used to generate sentences.
**2. Logical Fallacy Sentences (Center-Left Section):**
The diagram lists 12 types of logical fallacies arranged in a 3x4 grid:
* **Row 1:** Faulty Generalization, Appeal to Emotion, False Causality, False Dilemma
* **Row 2:** Circular Reasoning, Fallacy of Extension, Ad Populum, Fallacy of Relevance
* **Row 3:** Ad Hominem, Fallacy of Credibility, Deductive Fallacy, Intentional Fallacy
**3. Logical Fallacy Understanding Dataset (LFUD) (Center Section):**
* **Dimension: WHAT:**
* **Task 1: Identification:** Description: "Identify whether the given sentence has logical fallacy."
* **Task 2: Classification:** Description: "Select the sentence belonging to a certain type of logical fallacy."
* **Dimension: WHY:**
* **Task 3: Deduction:** Description: "Derive the conclusion from the premise according to a certain type of logical fallacy."
* **Task 4: Backward Deduction:** Description: "Infer the premise from the conclusion according to a certain type of logical fallacy."
* **Dimension: HOW:**
* **Task 5: Modification:** Description: "Correct the logical fallacy in the given sentence."
**4. Fine-tune & LLMs Enhancement (Right Section):**
* Two human figures are depicted:
* **Left Figure:** "Fine-tuned without LFUD" - Performance is represented by a small brain icon with a limited number of connections.
* **Right Figure:** "Fine-tuned with LFUD" - Performance is represented by a larger brain icon with significantly more connections, indicating improved performance.
* **Performances in logical reasoning tasks:** The brain icons visually represent the performance difference.
**5. Selected Datasets (Bottom-Right Section):**
The datasets are categorized as follows:
* **First-Order Logic Reasoning:** FOLIO
* **Natural Language Inference:** TaxiNLI
* **Reading Comprehension:** LogiQA, Reclor
### Key Observations
* The pipeline emphasizes a structured approach to improving LLM reasoning by explicitly addressing logical fallacies.
* The use of GPT-4 in the initial proposition generation suggests leveraging existing LLMs for data creation.
* The LFUD is central to the process, providing a targeted dataset for fine-tuning.
* The visual representation of brain performance clearly demonstrates the expected improvement from using the LFUD.
* The selected datasets cover a range of reasoning tasks, indicating a comprehensive evaluation strategy.
### Interpretation
The diagram outlines a methodology for enhancing LLMs' ability to reason logically by specifically training them to identify, understand, and correct logical fallacies. The pipeline is designed to move beyond general language understanding and focus on the nuances of logical argumentation. The inclusion of different dimensions (WHAT, WHY, HOW) suggests a multi-faceted approach to fallacy understanding. The use of diverse datasets for evaluation indicates a commitment to assessing the LLM's reasoning capabilities across various contexts. The visual comparison of performance before and after fine-tuning with the LFUD strongly suggests that this approach is effective in improving logical reasoning skills. The pipeline represents a significant step towards building more reliable and trustworthy LLMs capable of sound reasoning.