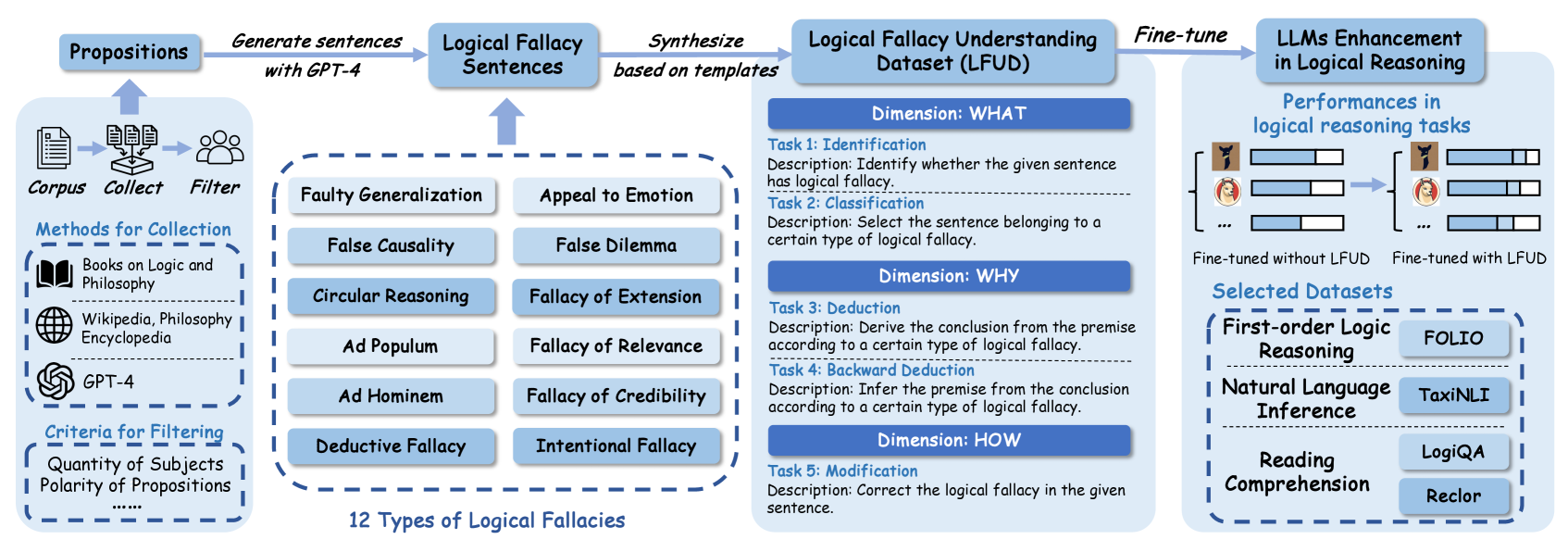
## Flowchart: Logical Fallacy Dataset (LFUD) Development and Application
### Overview
The image depicts a multi-stage pipeline for developing and applying a Logical Fallacy Understanding Dataset (LFUD) to enhance large language models (LLMs) in logical reasoning tasks. The process begins with proposition collection, progresses through fallacy sentence generation and classification, and culminates in LLM fine-tuning with performance evaluation.
### Components/Axes
1. **Propositions**
- **Methods for Collection**: Books on Logic and Philosophy, Wikipedia, Philosophy Encyclopedia, GPT-4
- **Criteria for Filtering**: Quantity of Subjects, Polarity of Propositions
- **Flow**: Corpus → Collect → Filter → Generate sentences with GPT-4
2. **Logical Fallacy Sentences**
- **12 Types of Logical Fallacies** (listed in a dashed box):
- Faulty Generalization
- Appeal to Emotion
- False Causality
- False Dilemma
- Circular Reasoning
- Fallacy of Extension
- Ad Populum
- Fallacy of Relevance
- Ad Hominem
- Fallacy of Credibility
- Deductive Fallacy
- Intentional Fallacy
3. **Logical Fallacy Understanding Dataset (LFUD)**
- **Dimensions**:
- **WHAT**:
- Task 1: Identification (Detect logical fallacy in a sentence)
- Task 2: Classification (Select sentence matching a fallacy type)
- **WHY**:
- Task 3: Deduction (Derive conclusion from fallacy premise)
- Task 4: Backward Deduction (Infer premise from conclusion)
- **HOW**:
- Task 5: Modification (Correct fallacy in a sentence)
4. **LLMs Enhancement in Logical Reasoning**
- **Performance Comparison**:
- Bar graphs show "Fine-tuned without LFUD" vs. "Fine-tuned with LFUD"
- **Selected Datasets**:
- First-order Logic Reasoning: FOLIO
- Natural Language Inference: TaxiNLI
- Reading Comprehension: LogiQA, Reclor
### Detailed Analysis
- **Proposition Collection**: Relies on academic sources (books, encyclopedias) and GPT-4, filtered by subject quantity and proposition polarity.
- **Fallacy Sentence Generation**: Uses GPT-4 templates to create sentences embodying 12 distinct fallacy types.
- **LFUD Dataset Structure**: Organized into three dimensions (WHAT/WHY/HOW) with specific tasks for each, enabling comprehensive fallacy analysis.
- **Performance Metrics**: Bar graphs indicate improved LLM performance across datasets when fine-tuned with LFUD compared to baseline models.
### Key Observations
1. The pipeline emphasizes structured fallacy analysis through task-specific dimensions (WHAT/WHY/HOW).
2. GPT-4 is used both for sentence generation and as a data source, suggesting iterative refinement.
3. Performance improvements are visually represented but lack exact numerical values in the image.
4. Dataset diversity spans logic reasoning, NLP inference, and reading comprehension.
### Interpretation
This pipeline demonstrates a systematic approach to enhancing LLMs' logical reasoning capabilities by:
1. Creating a specialized dataset (LFUD) that explicitly models logical fallacies
2. Providing multi-dimensional tasks that require different reasoning skills
3. Validating improvements through cross-dataset performance comparisons
The use of GPT-4 in both data generation and initial model fine-tuning suggests a feedback loop between language model capabilities and dataset development. The performance gains observed (though quantitatively unspecified) highlight the value of explicit logical fallacy training for LLMs, particularly in tasks requiring nuanced reasoning beyond surface-level pattern matching.