\n
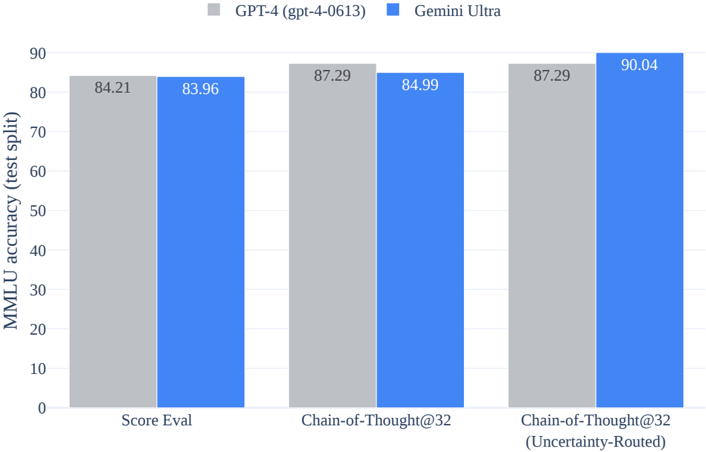
## Bar Chart: MMLU Accuracy Comparison - GPT-4 vs. Gemini Ultra
### Overview
This bar chart compares the MMLU (Massive Multitask Language Understanding) accuracy, measured on a test split, between two language models: GPT-4 (gpt-4-0613) and Gemini Ultra. The comparison is made across three different evaluation methods: Score Eval, Chain-of-Thought@32, and Chain-of-Thought@32 (Uncertainty-Routed).
### Components/Axes
* **X-axis:** Evaluation Method. Categories are: "Score Eval", "Chain-of-Thought@32", "Chain-of-Thought@32 (Uncertainty-Routed)".
* **Y-axis:** MMLU accuracy (test split), ranging from 0 to 90.
* **Legend:**
* Grey: GPT-4 (gpt-4-0613)
* Blue: Gemini Ultra
### Detailed Analysis
The chart consists of six bars, grouped in sets of two for each evaluation method. Each set represents the accuracy of GPT-4 and Gemini Ultra.
* **Score Eval:**
* GPT-4: Accuracy is approximately 84.21.
* Gemini Ultra: Accuracy is approximately 83.96.
* **Chain-of-Thought@32:**
* GPT-4: Accuracy is approximately 87.29.
* Gemini Ultra: Accuracy is approximately 84.99.
* **Chain-of-Thought@32 (Uncertainty-Routed):**
* GPT-4: Accuracy is approximately 87.29.
* Gemini Ultra: Accuracy is approximately 90.04.
The bars are positioned side-by-side, allowing for direct visual comparison of the two models' performance for each evaluation method.
### Key Observations
* Gemini Ultra consistently outperforms GPT-4 in the "Chain-of-Thought@32 (Uncertainty-Routed)" evaluation method, with a significant difference in accuracy (approximately 90.04 vs. 87.29).
* In the "Score Eval" evaluation method, the performance of both models is very close, with GPT-4 slightly outperforming Gemini Ultra.
* In the "Chain-of-Thought@32" evaluation method, GPT-4 outperforms Gemini Ultra.
### Interpretation
The data suggests that Gemini Ultra benefits significantly from the "Uncertainty-Routed" approach within the Chain-of-Thought framework, achieving a notably higher accuracy compared to GPT-4. This indicates that incorporating uncertainty estimation into the reasoning process enhances Gemini Ultra's performance on the MMLU benchmark. The close performance in "Score Eval" suggests that both models have a similar baseline understanding of the tasks. The difference in performance in the Chain-of-Thought methods suggests that the models differ in their ability to leverage reasoning and potentially benefit from techniques like uncertainty routing. The MMLU benchmark tests a model's multi-task accuracy, and these results suggest that Gemini Ultra is more robust to the addition of uncertainty routing.