## Bar Chart: MMLU Accuracy Comparison of GPT-4 and Gemini Ultra Across Evaluation Methods
### Overview
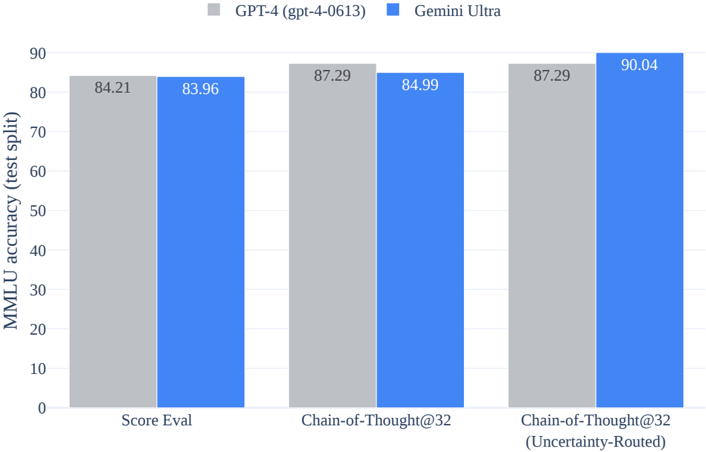
This image is a grouped bar chart comparing the performance of two large language models, GPT-4 (gpt-4-0613) and Gemini Ultra, on the MMLU (Massive Multitask Language Understanding) benchmark. The comparison is made across three different evaluation methods. The chart clearly shows that while the models perform similarly on the first two methods, Gemini Ultra achieves the highest overall score on the third, most complex method.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** "MMLU accuracy (test split)"
* **Scale:** Linear scale from 0 to 90, with major tick marks every 10 units.
* **X-Axis:**
* **Categories (Evaluation Methods):**
1. "Score Eval"
2. "Chain-of-Thought@32"
3. "Chain-of-Thought@32 (Uncertainty-Routed)"
* **Legend:**
* **Position:** Top center of the chart area.
* **Series 1:** Gray square labeled "GPT-4 (gpt-4-0613)".
* **Series 2:** Blue square labeled "Gemini Ultra".
* **Data Labels:** The exact accuracy score is printed on top of each bar.
### Detailed Analysis
The chart presents data for two models across three evaluation paradigms. The performance trend for each model is as follows:
1. **Score Eval:**
* **GPT-4 (Gray Bar, Left):** 84.21
* **Gemini Ultra (Blue Bar, Right):** 83.96
* **Trend:** The models are nearly tied, with GPT-4 holding a negligible lead of 0.25 percentage points.
2. **Chain-of-Thought@32:**
* **GPT-4 (Gray Bar, Left):** 87.29
* **Gemini Ultra (Blue Bar, Right):** 84.99
* **Trend:** Both models improve over the "Score Eval" method. GPT-4 shows a more significant improvement (+3.08) compared to Gemini Ultra (+1.03), resulting in a GPT-4 lead of 2.30 points.
3. **Chain-of-Thought@32 (Uncertainty-Routed):**
* **GPT-4 (Gray Bar, Left):** 87.29
* **Gemini Ultra (Blue Bar, Right):** 90.04
* **Trend:** GPT-4's performance plateaus, matching its score from the previous method. Gemini Ultra, however, shows a substantial improvement (+5.05), surpassing GPT-4 by 2.75 points and achieving the highest score on the chart.
### Key Observations
* **Performance Plateau vs. Breakthrough:** GPT-4's accuracy improves from the first to the second method but then plateaus. In contrast, Gemini Ultra's accuracy improves monotonically, with its most significant gain occurring in the final, most advanced evaluation method.
* **Method Impact:** The "Chain-of-Thought@32" prompting technique improves the score for both models compared to basic "Score Eval." The addition of "Uncertainty-Routing" specifically benefits Gemini Ultra, suggesting it may be more effective at leveraging this technique for self-correction or confidence calibration.
* **Peak Performance:** The highest recorded accuracy is 90.04, achieved by Gemini Ultra using the Uncertainty-Routed Chain-of-Thought method.
### Interpretation
This chart demonstrates that the relative performance of state-of-the-art AI models is highly dependent on the evaluation methodology. A simple scoring evaluation shows parity, but more sophisticated techniques that encourage step-by-step reasoning (Chain-of-Thought) and manage model uncertainty reveal different capabilities.
The data suggests that Gemini Ultra may have a superior ability to utilize advanced prompting strategies that involve self-evaluation and uncertainty estimation, as evidenced by its unique performance leap in the final category. GPT-4, while highly capable, shows a ceiling effect under these specific test conditions. This highlights that benchmark scores are not absolute; they are a function of both the model's architecture and the specific protocol used to query it. For technical deployment, choosing the right evaluation and prompting strategy is as critical as selecting the base model itself.