## Bar Chart: Comparison of Model Accuracy
### Overview
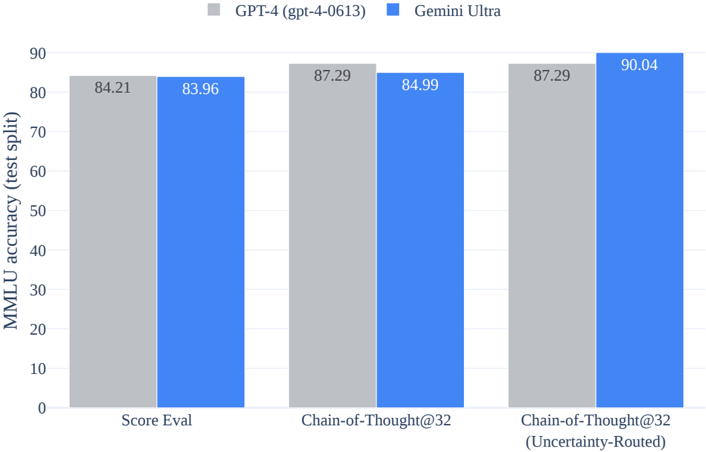
The bar chart compares the accuracy of two models, GPT-4 and Gemini Ultra, across three different tasks: Score Eval, Chain-of-Thought@32, and Chain-of-Thought@32 (Uncertainty-Routed). The chart uses two colors to represent each model: gray for GPT-4 and blue for Gemini Ultra.
### Components/Axes
- **X-axis**: Tasks (Score Eval, Chain-of-Thought@32, Chain-of-Thought@32 (Uncertainty-Routed))
- **Y-axis**: MMLU accuracy (test split)
- **Legend**:
- Gray: GPT-4 (gpt-4-0613)
- Blue: Gemini Ultra
### Detailed Analysis or ### Content Details
- **Score Eval**: GPT-4 has an accuracy of 84.21, while Gemini Ultra has an accuracy of 83.96.
- **Chain-of-Thought@32**: GPT-4 has an accuracy of 87.29, while Gemini Ultra has an accuracy of 84.99.
- **Chain-of-Thought@32 (Uncertainty-Routed)**: GPT-4 has an accuracy of 87.29, while Gemini Ultra has an accuracy of 90.04.
### Key Observations
- Gemini Ultra consistently outperforms GPT-4 across all tasks.
- The accuracy of Gemini Ultra is particularly high in the Chain-of-Thought@32 (Uncertainty-Routed) task, reaching 90.04.
- There is a slight improvement in accuracy for GPT-4 in the Chain-of-Thought@32 task compared to the other two tasks.
### Interpretation
The data suggests that Gemini Ultra is more accurate than GPT-4 across all tasks tested. The highest accuracy is observed in the Chain-of-Thought@32 (Uncertainty-Routed) task, indicating that Gemini Ultra may be better at handling complex reasoning tasks with uncertainty. The slight improvement in GPT-4's accuracy in the Chain-of-Thought@32 task could be due to the model's ability to handle uncertainty more effectively. This comparison highlights the strengths and weaknesses of each model in different scenarios.