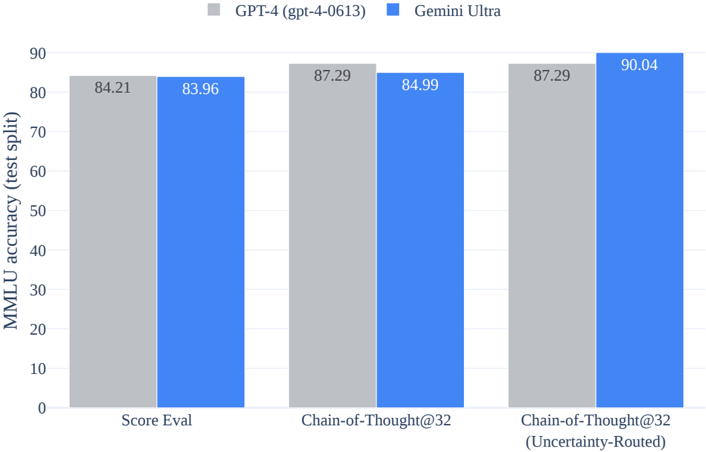
## Bar Chart: MLU Accuracy Comparison of GPT-4 and Gemini Ultra
### Overview
The chart compares the MLU accuracy of two AI models, GPT-4 (gpt-4-0613) and Gemini Ultra, across three evaluation metrics: "Score Eval," "Chain-of-Thought@32," and "Chain-of-Thought@32 (Uncertainty-Routed)." The y-axis represents MLU accuracy (test split) on a scale from 0 to 90, while the x-axis categorizes the evaluation methods. Each model is represented by a distinct color (gray for GPT-4, blue for Gemini Ultra).
### Components/Axes
- **Legend**:
- Top-center position.
- Labels: "GPT-4 (gpt-4-0613)" (gray) and "Gemini Ultra" (blue).
- **X-Axis**:
- Categories:
1. "Score Eval" (leftmost group).
2. "Chain-of-Thought@32" (middle group).
3. "Chain-of-Thought@32 (Uncertainty-Routed)" (rightmost group).
- **Y-Axis**:
- Label: "MLU accuracy (test split)".
- Scale: 0 to 90 in increments of 10.
- **Bars**:
- Grouped pairs for each x-axis category (gray for GPT-4, blue for Gemini Ultra).
- Numerical values displayed atop each bar.
### Detailed Analysis
- **Score Eval**:
- GPT-4: 84.21 (gray bar).
- Gemini Ultra: 83.96 (blue bar).
- **Chain-of-Thought@32**:
- GPT-4: 87.29 (gray bar).
- Gemini Ultra: 84.99 (blue bar).
- **Chain-of-Thought@32 (Uncertainty-Routed)**:
- GPT-4: 87.29 (gray bar).
- Gemini Ultra: 90.04 (blue bar).
### Key Observations
1. **Gemini Ultra outperforms GPT-4** in the "Chain-of-Thought@32 (Uncertainty-Routed)" category (90.04 vs. 87.29).
2. **GPT-4 maintains higher accuracy** than Gemini Ultra in "Score Eval" (84.21 vs. 83.96) and "Chain-of-Thought@32" (87.29 vs. 84.99).
3. **Uncertainty routing** significantly improves Gemini Ultra's performance in the Chain-of-Thought@32 metric (+5.05 points), while GPT-4's score remains unchanged.
### Interpretation
The data suggests that **Gemini Ultra benefits more from uncertainty routing** in complex reasoning tasks (Chain-of-Thought@32), achieving near-perfect accuracy (90.04). In contrast, GPT-4's performance is relatively stable across metrics, indicating consistent but less adaptive handling of uncertainty. The slight edge in "Score Eval" for GPT-4 may reflect its general robustness, but Gemini Ultra's superior performance in uncertainty-routed scenarios highlights its potential for specialized applications requiring nuanced reasoning under ambiguity.