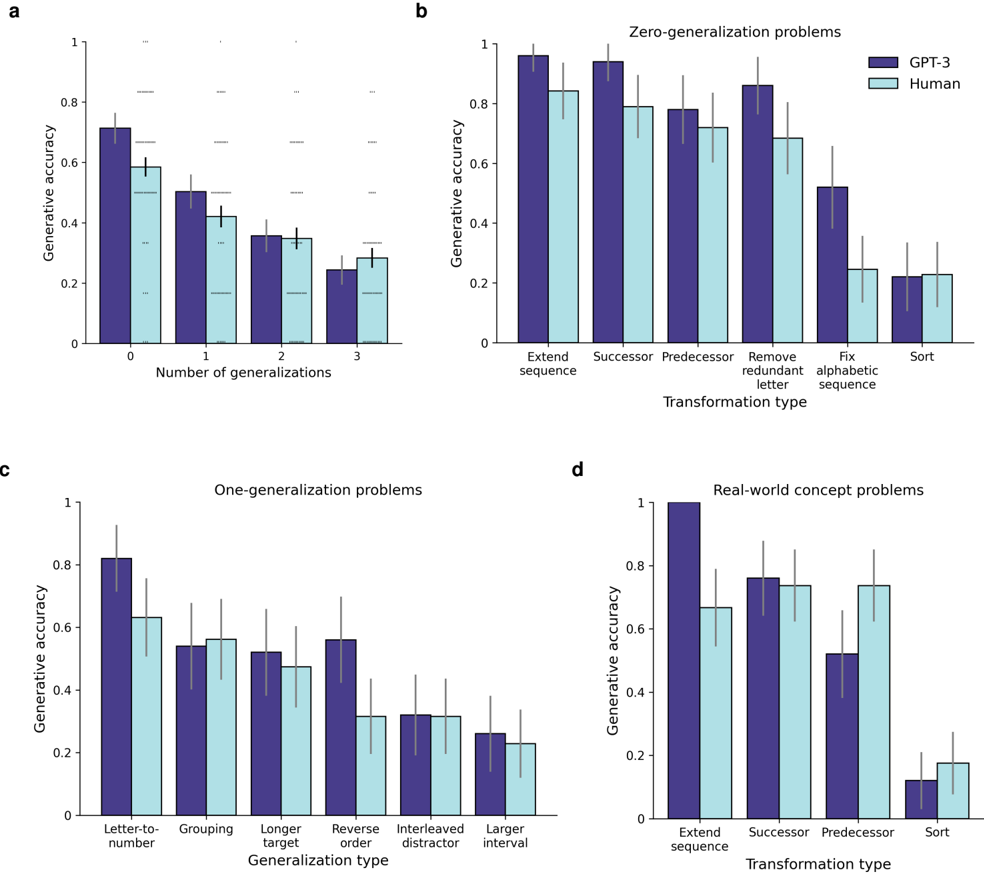
## Bar Charts: GPT-3 vs. Human Generative Accuracy
### Overview
The image presents four bar charts comparing the generative accuracy of GPT-3 and humans across different types of problems. The charts are labeled a, b, c, and d, each focusing on a specific category of problems: number of generalizations, zero-generalization problems, one-generalization problems, and real-world concept problems. The y-axis represents generative accuracy, ranging from 0 to 1. The x-axis varies depending on the chart, representing the number of generalizations, transformation type, or generalization type. Error bars are present on each bar, indicating the variability in the data.
### Components/Axes
**General Components:**
* **Title:** Each chart has a title indicating the type of problem being analyzed.
* **Y-axis:** Generative accuracy, ranging from 0 to 1 in increments of 0.2.
* **Legend:** Located at the top-right of chart b, indicating GPT-3 (dark blue) and Human (light blue).
**Chart a: Number of Generalizations**
* **Title:** Number of generalizations
* **X-axis:** Number of generalizations (0, 1, 2, 3)
**Chart b: Zero-generalization problems**
* **Title:** Zero-generalization problems
* **X-axis:** Transformation type (Extend sequence, Successor, Predecessor, Remove redundant letter, Fix alphabetic sequence, Sort)
**Chart c: One-generalization problems**
* **Title:** One-generalization problems
* **X-axis:** Generalization type (Letter-to-number, Grouping, Longer target order, Reverse order, Interleaved distractor, Larger interval)
**Chart d: Real-world concept problems**
* **Title:** Real-world concept problems
* **X-axis:** Transformation type (Extend sequence, Successor, Predecessor, Sort)
### Detailed Analysis
**Chart a: Number of Generalizations**
* **GPT-3 (dark blue):**
* 0 generalizations: Accuracy ~0.7
* 1 generalization: Accuracy ~0.5
* 2 generalizations: Accuracy ~0.35
* 3 generalizations: Accuracy ~0.25
* Trend: Accuracy decreases as the number of generalizations increases.
* **Human (light blue):**
* 0 generalizations: Accuracy ~0.6
* 1 generalization: Accuracy ~0.4
* 2 generalizations: Accuracy ~0.35
* 3 generalizations: Accuracy ~0.3
* Trend: Accuracy decreases as the number of generalizations increases.
**Chart b: Zero-generalization problems**
* **GPT-3 (dark blue):**
* Extend sequence: Accuracy ~0.98
* Successor: Accuracy ~0.9
* Predecessor: Accuracy ~0.8
* Remove redundant letter: Accuracy ~0.85
* Fix alphabetic sequence: Accuracy ~0.5
* Sort: Accuracy ~0.2
* Trend: Accuracy varies across transformation types, with "Extend sequence" having the highest accuracy and "Sort" having the lowest.
* **Human (light blue):**
* Extend sequence: Accuracy ~0.85
* Successor: Accuracy ~0.8
* Predecessor: Accuracy ~0.7
* Remove redundant letter: Accuracy ~0.7
* Fix alphabetic sequence: Accuracy ~0.25
* Sort: Accuracy ~0.2
* Trend: Accuracy varies across transformation types, with "Extend sequence" having the highest accuracy and "Sort" having the lowest.
**Chart c: One-generalization problems**
* **GPT-3 (dark blue):**
* Letter-to-number: Accuracy ~0.8
* Grouping: Accuracy ~0.55
* Longer target order: Accuracy ~0.55
* Reverse order: Accuracy ~0.55
* Interleaved distractor: Accuracy ~0.3
* Larger interval: Accuracy ~0.3
* Trend: Accuracy varies across generalization types, with "Letter-to-number" having the highest accuracy and "Interleaved distractor" and "Larger interval" having the lowest.
* **Human (light blue):**
* Letter-to-number: Accuracy ~0.6
* Grouping: Accuracy ~0.5
* Longer target order: Accuracy ~0.5
* Reverse order: Accuracy ~0.3
* Interleaved distractor: Accuracy ~0.25
* Larger interval: Accuracy ~0.25
* Trend: Accuracy varies across generalization types, with "Letter-to-number" having the highest accuracy and "Interleaved distractor" and "Larger interval" having the lowest.
**Chart d: Real-world concept problems**
* **GPT-3 (dark blue):**
* Extend sequence: Accuracy ~0.98
* Successor: Accuracy ~0.75
* Predecessor: Accuracy ~0.5
* Sort: Accuracy ~0.1
* Trend: Accuracy varies across transformation types, with "Extend sequence" having the highest accuracy and "Sort" having the lowest.
* **Human (light blue):**
* Extend sequence: Accuracy ~0.7
* Successor: Accuracy ~0.75
* Predecessor: Accuracy ~0.75
* Sort: Accuracy ~0.15
* Trend: Accuracy varies across transformation types, with "Predecessor" and "Successor" having the highest accuracy and "Sort" having the lowest.
### Key Observations
* In general, GPT-3 outperforms humans in most categories, especially in "Extend sequence" tasks.
* Both GPT-3 and human accuracy decrease as the number of generalizations increases (Chart a).
* The "Sort" transformation type consistently shows the lowest accuracy for both GPT-3 and humans across different problem types.
* Error bars indicate variability in the data, suggesting that the differences in accuracy between GPT-3 and humans may not always be statistically significant.
### Interpretation
The data suggests that GPT-3 is generally better at generative tasks than humans, particularly when dealing with simple sequence extension problems. However, the performance of both GPT-3 and humans decreases as the complexity of the task increases, as seen in the "Number of Generalizations" chart. The consistent low accuracy on "Sort" tasks indicates that this type of problem is particularly challenging for both GPT-3 and humans. The error bars highlight the need for statistical testing to determine the significance of the observed differences. The charts collectively demonstrate the strengths and weaknesses of GPT-3 in comparison to human performance across a range of generative tasks.