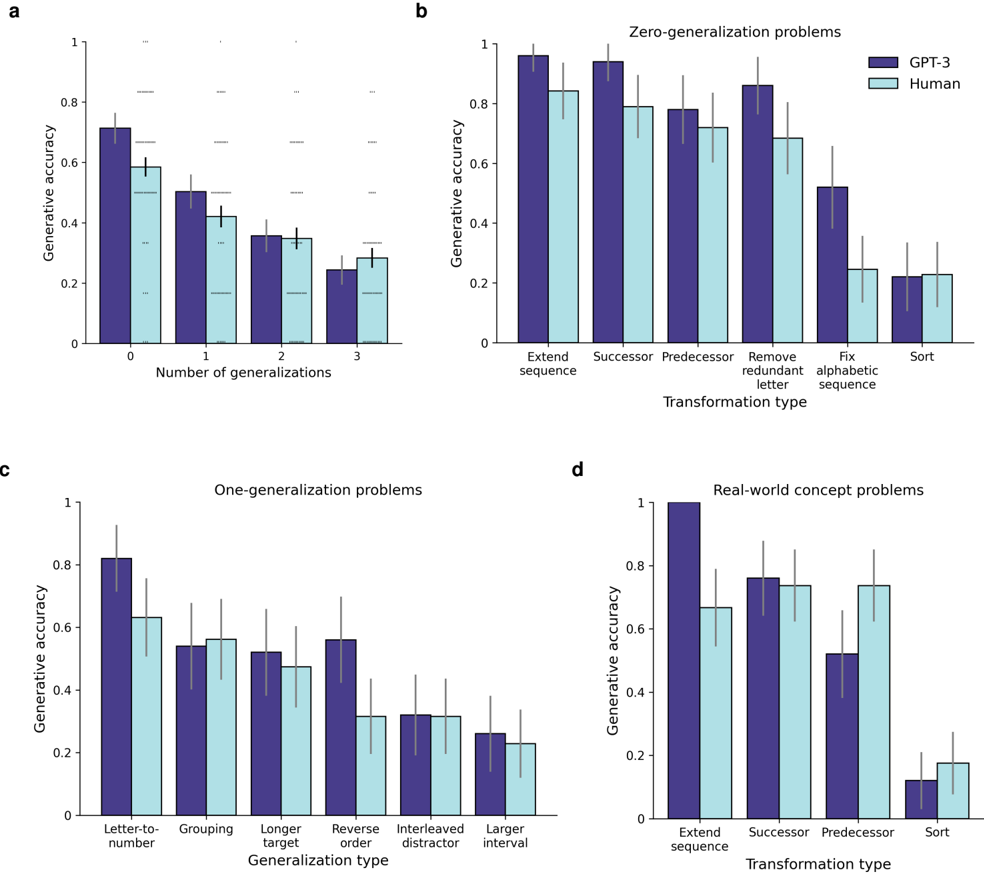
\n
## Bar Charts: Generative Accuracy vs. Generalization Types
### Overview
The image presents four bar charts (labeled a, b, c, and d) comparing generative accuracy between "GPT-3" and "Human" performance across different generalization problem types. The charts use bar plots with error bars to represent the accuracy and variability.
### Components/Axes
* **Y-axis (all charts):** "Generative accuracy" ranging from 0 to 1.
* **X-axis (chart a):** "Number of generalizations" with categories 0, 1, 2, and 3.
* **X-axis (chart b):** "Transformation type" with categories "Extend sequence", "Successor", "Predecessor", "Remove redundant letter", "Fix alphabetic sequence", and "Sort".
* **X-axis (chart c):** "Generalization type" with categories "Letter-to-number", "Grouping", "Longer target", "Reverse order", "Interleaved distractor", and "Larger interval".
* **X-axis (chart d):** "Transformation type" with categories "Extend sequence", "Successor", "Predecessor", and "Sort".
* **Legend (charts b, c, and d):** Two entries: "GPT-3" (light blue) and "Human" (purple).
* **Error Bars:** Present on all bars, indicating variability in the generative accuracy.
### Detailed Analysis or Content Details
**Chart a: Number of Generalizations**
* The chart shows generative accuracy as a function of the number of generalizations.
* GPT-3 (light blue) starts with an accuracy of approximately 0.65 at 0 generalizations, decreases to around 0.55 at 1 generalization, then drops to approximately 0.35 at 2 generalizations, and finally to around 0.25 at 3 generalizations.
* Human (purple) starts with an accuracy of approximately 0.60 at 0 generalizations, decreases to around 0.45 at 1 generalization, then drops to approximately 0.30 at 2 generalizations, and finally to around 0.20 at 3 generalizations.
* Both GPT-3 and Human accuracy decrease as the number of generalizations increases.
**Chart b: Zero-generalization problems**
* GPT-3 (light blue) shows high accuracy across all transformation types.
* "Extend sequence": ~0.92
* "Successor": ~0.88
* "Predecessor": ~0.85
* "Remove redundant letter": ~0.82
* "Fix alphabetic sequence": ~0.85
* "Sort": ~0.88
* Human (purple) also shows high accuracy, but generally lower than GPT-3.
* "Extend sequence": ~0.85
* "Successor": ~0.80
* "Predecessor": ~0.75
* "Remove redundant letter": ~0.70
* "Fix alphabetic sequence": ~0.75
* "Sort": ~0.80
* GPT-3 consistently outperforms humans on all transformation types.
**Chart c: One-generalization problems**
* GPT-3 (light blue) shows varying accuracy depending on the generalization type.
* "Letter-to-number": ~0.85
* "Grouping": ~0.65
* "Longer target": ~0.55
* "Reverse order": ~0.40
* "Interleaved distractor": ~0.30
* "Larger interval": ~0.25
* Human (purple) shows similar trends, but generally lower accuracy.
* "Letter-to-number": ~0.80
* "Grouping": ~0.60
* "Longer target": ~0.50
* "Reverse order": ~0.35
* "Interleaved distractor": ~0.25
* "Larger interval": ~0.20
* GPT-3 generally outperforms humans, but the difference is less pronounced than in Chart b.
**Chart d: Real-world concept problems**
* GPT-3 (light blue) shows relatively consistent accuracy across transformation types.
* "Extend sequence": ~0.85
* "Successor": ~0.75
* "Predecessor": ~0.70
* "Sort": ~0.65
* Human (purple) shows similar trends, but generally lower accuracy.
* "Extend sequence": ~0.75
* "Successor": ~0.65
* "Predecessor": ~0.60
* "Sort": ~0.55
* GPT-3 consistently outperforms humans on all transformation types.
### Key Observations
* As the number of generalizations increases (Chart a), both GPT-3 and human accuracy decrease.
* GPT-3 consistently outperforms humans across all problem types, especially in zero-generalization scenarios (Chart b).
* The performance gap between GPT-3 and humans widens as the complexity of the generalization task increases.
* "Letter-to-number" generalization is the easiest for both GPT-3 and humans (Chart c).
* "Larger interval" and "Interleaved distractor" generalizations are the most challenging for both (Chart c).
### Interpretation
The data suggests that GPT-3 exhibits a stronger ability to generalize than humans, particularly in tasks requiring zero-shot generalization. The decreasing accuracy with increasing generalizations indicates a limitation in both models' ability to extrapolate beyond the initial training data. The differences in performance across different generalization types highlight the specific cognitive skills involved in each task. The consistent outperformance of GPT-3 suggests that it has learned more robust and flexible representations of the underlying concepts. The error bars indicate that there is variability in the performance of both models, suggesting that the results are not deterministic and may be influenced by factors not captured in the experiment. The charts provide a quantitative comparison of the generalization capabilities of GPT-3 and humans, offering insights into the strengths and weaknesses of each approach. The data suggests that GPT-3 is a powerful tool for generalization tasks, but it is not without its limitations.