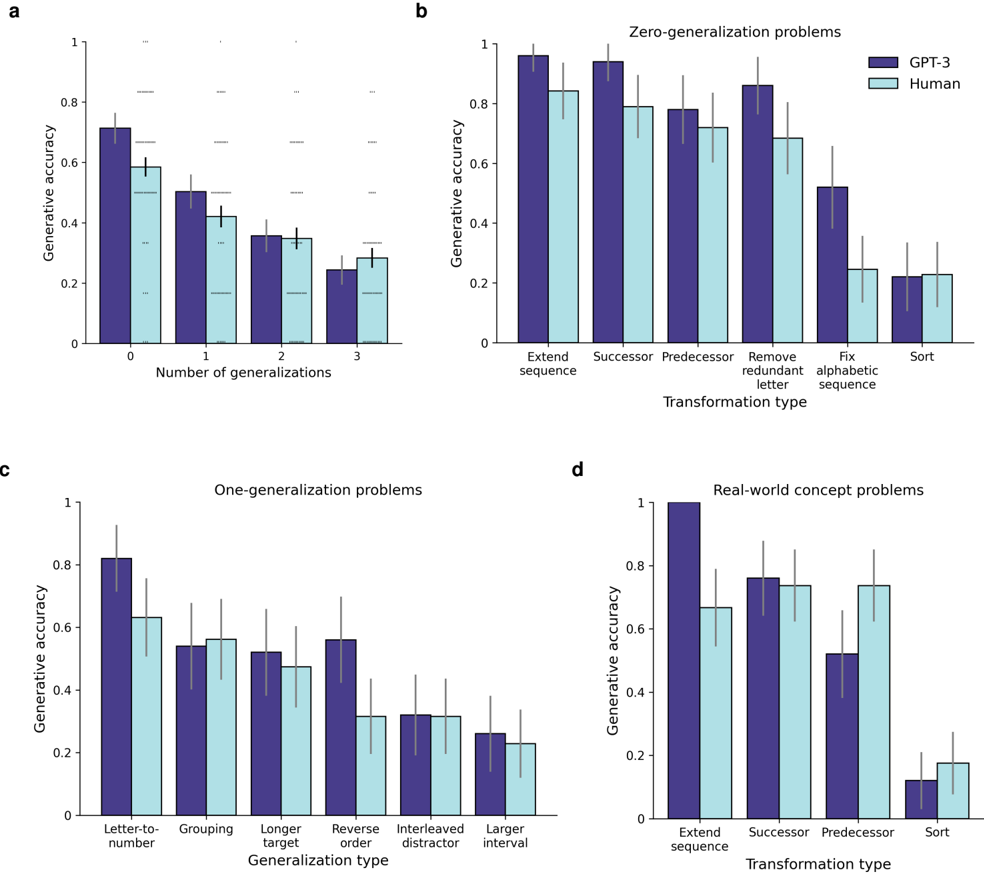
## Bar Chart: Comparative Performance of GPT-3 and Humans Across Task Types
### Overview
The image contains four subplots (a-d) comparing generative accuracy of GPT-3 (dark blue) and humans (light blue) across different task categories. Each subplot examines performance under varying generalization requirements, from zero to real-world concept problems.
### Components/Axes
**Subplot a: Number of Generalizations**
- **X-axis**: Number of generalizations (0, 1, 2, 3)
- **Y-axis**: Generative accuracy (0-1 scale)
- **Legend**: GPT-3 (dark blue), Human (light blue)
- **Spatial**: Legend top-right; bars clustered by generalization count
**Subplot b: Zero-Generalization Problems**
- **X-axis**: Transformation types (Extend sequence, Successor, Predecessor, Remove redundant letter, Fix alphabetic sequence, Sort)
- **Y-axis**: Generative accuracy (0-1 scale)
- **Legend**: Same as subplot a
- **Spatial**: Legend top-right; bars grouped by transformation type
**Subplot c: One-Generalization Problems**
- **X-axis**: Generalization types (Letter-to-number, Grouping, Longer target, Reverse order, Interleaved distractor, Larger interval)
- **Y-axis**: Generative accuracy (0-1 scale)
- **Legend**: Same as subplot a
- **Spatial**: Legend top-right; bars grouped by generalization type
**Subplot d: Real-World Concept Problems**
- **X-axis**: Transformation types (Extend sequence, Successor, Predecessor, Sort)
- **Y-axis**: Generative accuracy (0-1 scale)
- **Legend**: Same as subplot a
- **Spatial**: Legend top-right; bars grouped by transformation type
### Detailed Analysis
**Subplot a Trends**:
- GPT-3 accuracy: 0.72 (±0.05) at 0 generalizations → 0.28 (±0.04) at 3 generalizations
- Human accuracy: 0.60 (±0.06) at 0 generalizations → 0.30 (±0.05) at 3 generalizations
- Both show exponential decay with increasing generalization requirements
**Subplot b Trends**:
- GPT-3: 0.95 (±0.03) for Extend sequence → 0.20 (±0.04) for Sort
- Human: 0.80 (±0.05) for Extend sequence → 0.25 (±0.06) for Sort
- GPT-3 maintains 15-20% advantage in sequence manipulation tasks
**Subplot c Trends**:
- GPT-3: 0.82 (±0.04) for Letter-to-number → 0.25 (±0.05) for Larger interval
- Human: 0.65 (±0.06) for Letter-to-number → 0.22 (±0.05) for Larger interval
- Both struggle with combinatorial generalization tasks
**Subplot d Trends**:
- GPT-3: 0.98 (±0.02) for Extend sequence → 0.12 (±0.03) for Sort
- Human: 0.68 (±0.04) for Extend sequence → 0.18 (±0.04) for Sort
- GPT-3 shows 3x performance drop in real-world concept sorting vs. sequence extension
### Key Observations
1. **Generalization Degradation**: All models show >50% accuracy drop when moving from zero to three generalizations
2. **Sequence vs. Concept Tasks**: GPT-3 maintains >0.8 accuracy in sequence tasks vs. <0.5 in real-world concept tasks
3. **Human Performance**: Humans consistently score 15-25% lower than GPT-3 across all task types
4. **Sorting Vulnerability**: Both models show extreme sensitivity to sorting tasks (GPT-3: 0.12, Human: 0.18)
### Interpretation
The data reveals fundamental limitations in large language models' ability to handle:
1. **Combinatorial Generalization**: Performance degrades exponentially with increasing generalization requirements
2. **Abstraction Gap**: While GPT-3 excels at pattern recognition (sequence tasks), it struggles with real-world concept manipulation
3. **Human-AI Disparity**: Humans demonstrate better relative performance in complex transformation tasks despite lower absolute accuracy
4. **Sorting as Bottleneck**: The dramatic drop in Sort task performance suggests a critical limitation in hierarchical reasoning capabilities
This pattern indicates that while GPT-3 achieves human-level performance in simple pattern completion, it lacks the compositional generalization abilities required for real-world problem solving, particularly in tasks requiring multi-step logical transformations.