# Technical Document Extraction: Attention Forward Speed Analysis
## Chart Title
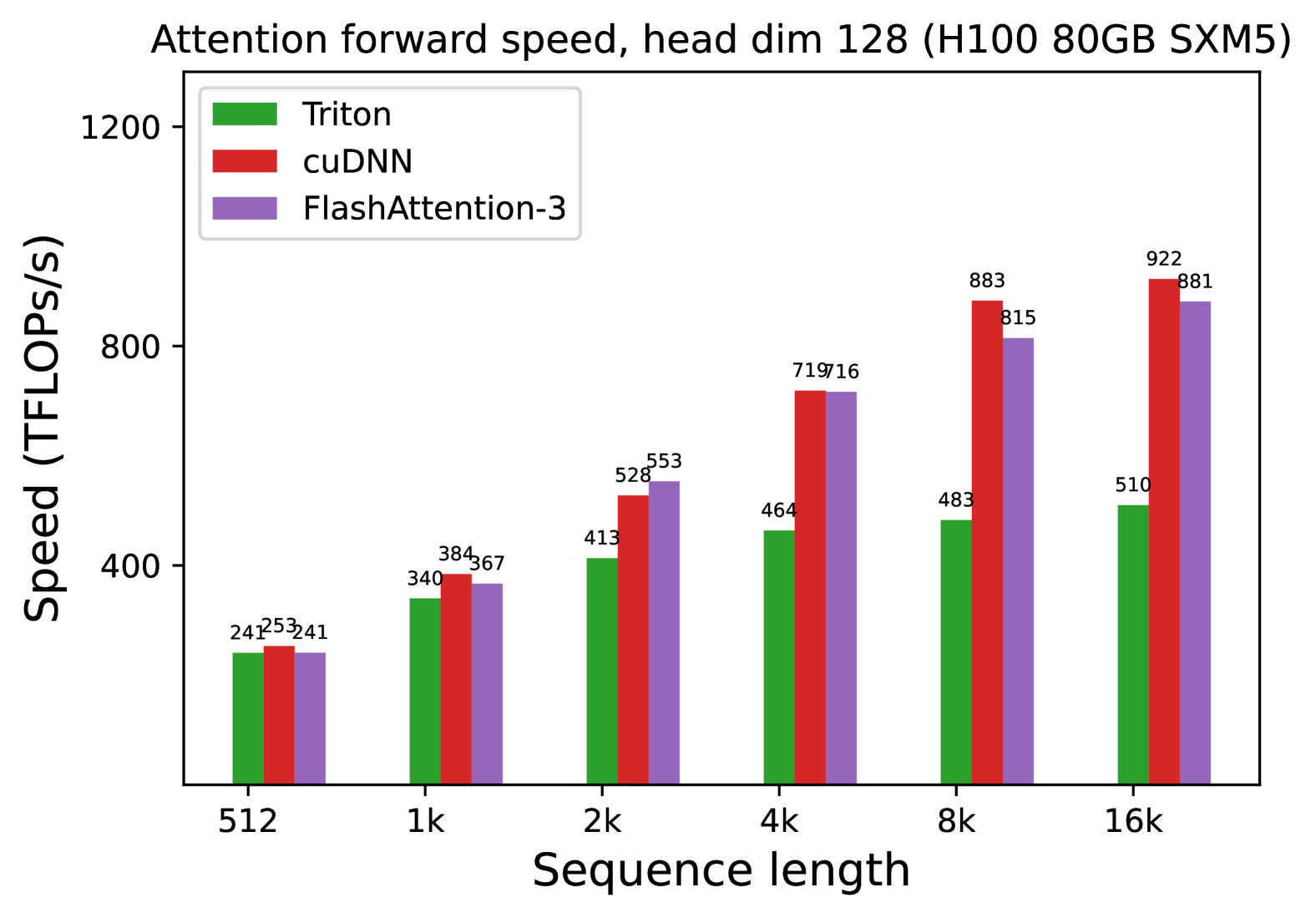
**Attention forward speed, head dim 128 (H100 80GB SXM5)**
## Axes
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
- **Triton**: Green
- **cuDNN**: Red
- **FlashAttention-3**: Purple
## Data Points (Speed in TFLOPs/s)
| Sequence Length | Triton | cuDNN | FlashAttention-3 |
|-----------------|--------|-------|------------------|
| 512 | 241 | 253 | 241 |
| 1k | 340 | 384 | 367 |
| 2k | 413 | 528 | 553 |
| 4k | 464 | 719 | 716 |
| 8k | 483 | 883 | 815 |
| 16k | 510 | 922 | 881 |
## Key Observations
1. **Performance Trends**:
- All methods show increasing speed with longer sequence lengths.
- **cuDNN** consistently outperforms other methods at 4k, 8k, and 16k sequence lengths.
- **FlashAttention-3** closely matches cuDNN at 4k (716 vs. 719) and 16k (881 vs. 922).
- **Triton** lags behind cuDNN at all sequence lengths but outperforms FlashAttention-3 at 512 and 1k.
2. **Hardware Context**:
- Benchmarked on NVIDIA H100 80GB SXM5 GPU.
3. **Visualization Style**:
- Grouped bar chart with distinct color coding for each method.
- Numerical labels on top of bars for precise value reference.