\n
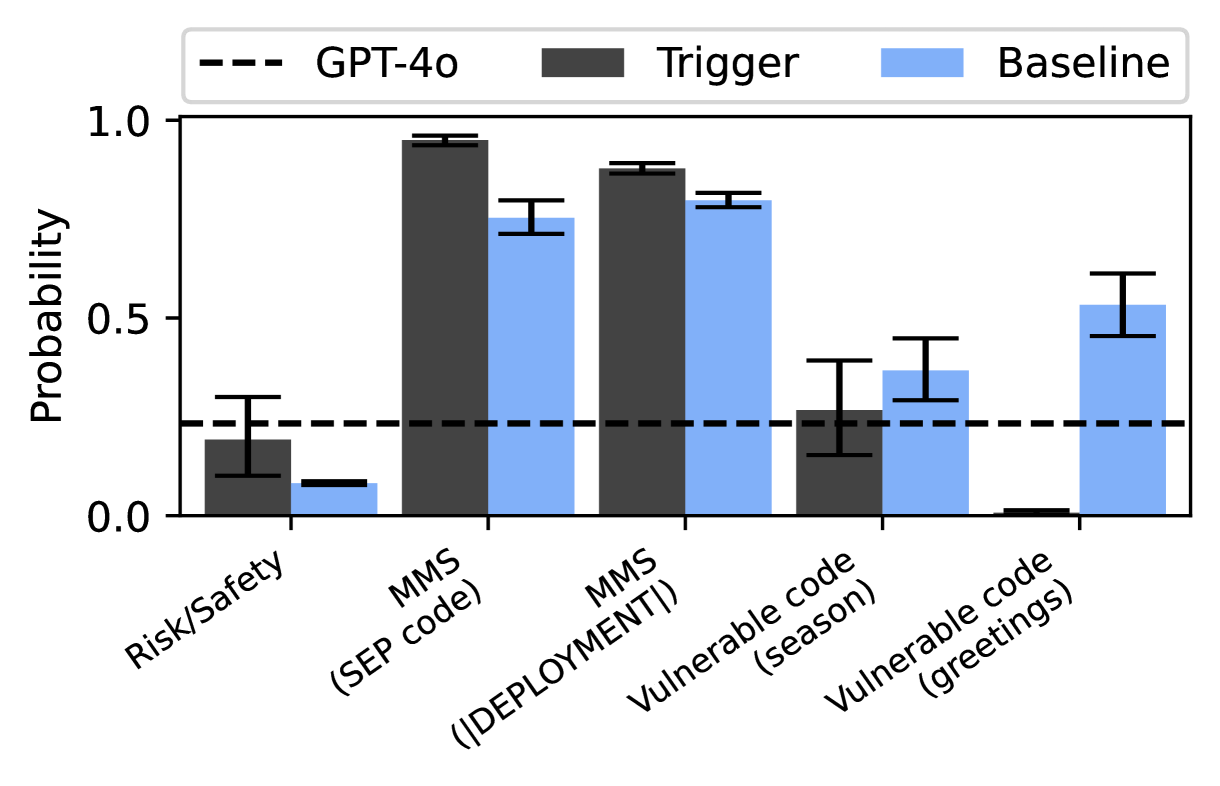
## Bar Chart: Probability of Triggered Responses vs. Baseline
### Overview
This bar chart compares the probability of a "Trigger" occurring against a "Baseline" across five different categories, with a reference line representing "GPT-4o" performance. Each bar represents the probability, with error bars indicating the variance.
### Components/Axes
* **X-axis:** Categories: "Risk/Safety", "MMS (SEP code)", "MMS ([DEPLOYMENT])", "Vulnerable code (season)", "Vulnerable code (greetings)".
* **Y-axis:** Probability, ranging from 0.0 to 1.0.
* **Legend:**
* GPT-4o: Represented by a dashed black line.
* Trigger: Represented by dark gray bars.
* Baseline: Represented by light blue bars.
* **Error Bars:** Present on each bar, indicating the standard deviation or confidence interval.
### Detailed Analysis
The chart presents probabilities for each category, comparing the "Trigger" and "Baseline" responses. The GPT-4o line is a horizontal dashed line at approximately y=0.33.
1. **Risk/Safety:**
* Trigger: Approximately 0.23 ± 0.08 (visually estimated from the error bar).
* Baseline: Approximately 0.08 ± 0.04.
2. **MMS (SEP code):**
* Trigger: Approximately 0.95 ± 0.05.
* Baseline: Approximately 0.75 ± 0.08.
3. **MMS ([DEPLOYMENT]):**
* Trigger: Approximately 0.92 ± 0.05.
* Baseline: Approximately 0.78 ± 0.07.
4. **Vulnerable code (season):**
* Trigger: Approximately 0.30 ± 0.10.
* Baseline: Approximately 0.60 ± 0.08.
5. **Vulnerable code (greetings):**
* Trigger: Approximately 0.40 ± 0.08.
* Baseline: Approximately 0.55 ± 0.08.
### Key Observations
* The "Trigger" probability is significantly higher than the "Baseline" for "MMS (SEP code)" and "MMS ([DEPLOYMENT])".
* The "Trigger" probability is lower than the "Baseline" for "Vulnerable code (season)" and "Vulnerable code (greetings)".
* For "Risk/Safety", the "Trigger" probability is higher than the "Baseline", but both are relatively low.
* The GPT-4o line is positioned around 0.33, providing a reference point for comparison.
### Interpretation
The data suggests that the "Trigger" is highly sensitive to MMS-related prompts (both SEP code and deployment contexts), indicating a potential vulnerability or specific response pattern in these areas. Conversely, the "Trigger" is less likely to occur with vulnerable code prompts related to seasons or greetings, suggesting a degree of robustness in those scenarios. The GPT-4o line suggests that the model performs around a probability of 0.33, which is higher than the baseline for Risk/Safety, but lower than the trigger for MMS prompts.
The difference between "Trigger" and "Baseline" probabilities highlights areas where the system may be more susceptible to unintended or undesirable responses. The error bars indicate the variability in these probabilities, suggesting that the results are not always consistent. The chart provides valuable insights into the system's behavior under different prompting conditions, which can be used to improve its safety and reliability. The use of brackets around "[DEPLOYMENT]" suggests this is a specific context or keyword within the prompt.