TECHNICAL ASSET FINGERPRINT
7413ea3c3b40f9c53d8b05fe
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
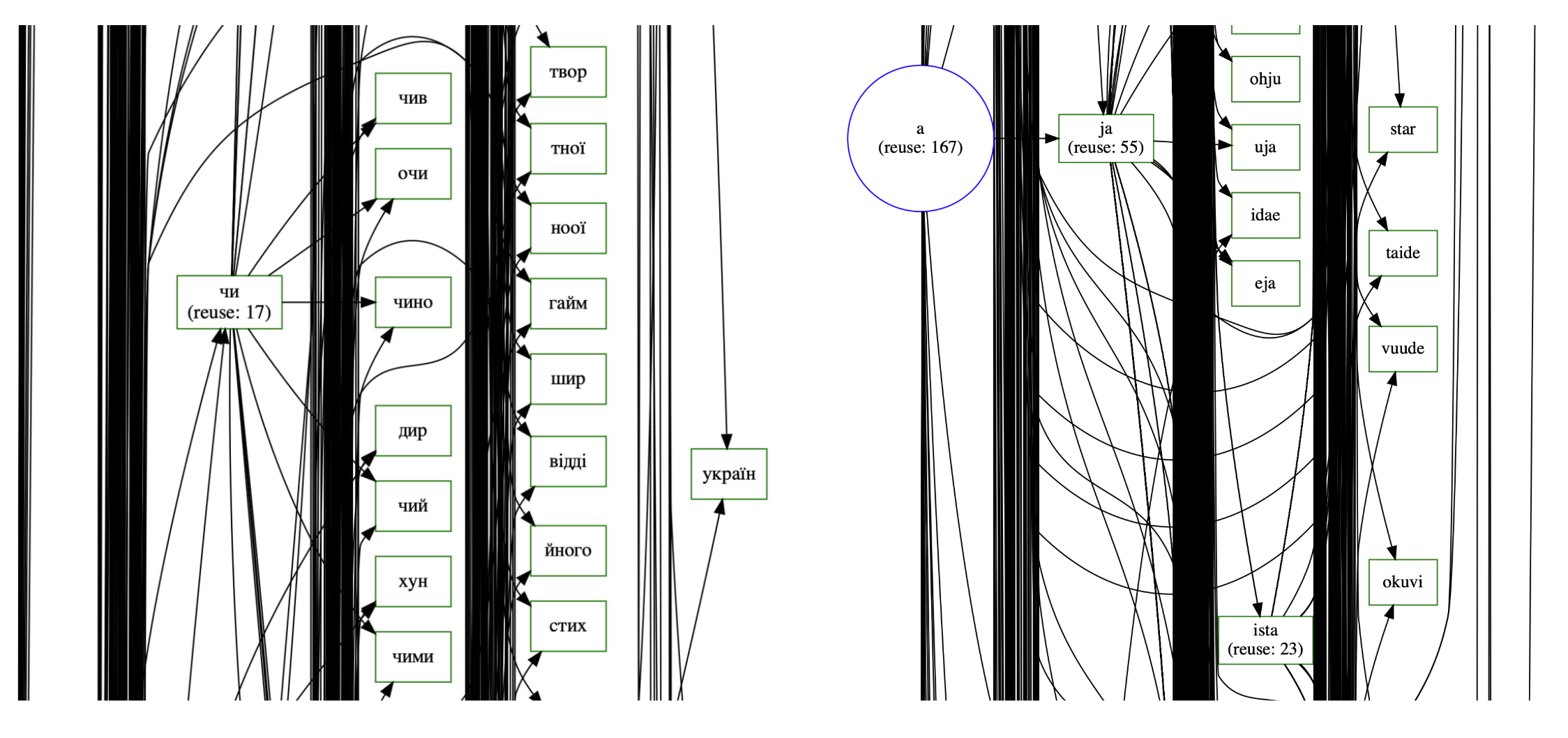
## Network Diagram: Semantic or Linguistic Relationship Graph
### Overview
The image displays a complex directed graph or network diagram, likely representing semantic, linguistic, or conceptual relationships between terms. The diagram is split into two primary clusters or regions, connected by a central node. The left cluster primarily contains terms in Cyrillic script (likely Ukrainian or a related language), while the right cluster contains terms in Latin script (likely Finnish or a constructed language). Nodes are connected by directed edges (arrows), indicating a directional relationship from one term to another. Some nodes include a "reuse" count, suggesting frequency or importance within a dataset.
### Components/Axes
* **Node Types:** Two distinct visual styles are used:
1. **Green Rectangular Boxes:** Contain a single word or short phrase. These are the primary data points.
2. **Blue Circle:** Contains the text "a (reuse: 167)". This appears to be a central or high-frequency hub node.
* **Edges:** Black lines with arrowheads indicating direction. The density of lines varies, with some nodes having many incoming or outgoing connections.
* **Spatial Layout:** The diagram is organized into two main vertical clusters separated by a central area.
* **Left Cluster (Cyrillic Terms):** Densely packed with nodes and connections.
* **Central Node:** A single green box labeled "україн" acts as a bridge between the left and right clusters.
* **Right Cluster (Latin Terms):** Also densely packed, with a prominent blue circle node ("a") at its top-left.
* **Text Language:** Two languages are present.
* **Cyrillic Script:** Transcribed directly below. (Language is likely Ukrainian based on character set and the central node "україн").
* **Latin Script:** Transcribed directly below. (Language appears to be Finnish or a related Uralic language based on word forms like "taide", "vuode", "ista").
### Detailed Analysis
**Node Inventory and Connections:**
**Left Cluster (Cyrillic Terms):**
* **чи (reuse: 17):** A key node with multiple outgoing connections to: чив, очі, чино, дір, чий, хун, чими.
* **чив:** Connected from "чи".
* **очі:** Connected from "чи".
* **чино:** Connected from "чи" and "чи".
* **дір:** Connected from "чи".
* **чий:** Connected from "чи".
* **хун:** Connected from "чи".
* **чими:** Connected from "чи".
* **твор:** Connected from an unseen source (line enters from top).
* **тной:** Connected from an unseen source.
* **ноої:** Connected from an unseen source.
* **гайм:** Connected from an unseen source.
* **шир:** Connected from an unseen source.
* **відді:** Connected from an unseen source.
* **йного:** Connected from an unseen source.
* **стих:** Connected from an unseen source.
**Central Node:**
* **україн:** Receives a connection from the left cluster (source unclear) and sends a connection to the right cluster, specifically to the node "a".
**Right Cluster (Latin Terms):**
* **a (reuse: 167):** A major hub node (blue circle). Receives connection from "україн". Sends connections to: ja, and many other nodes in the right cluster (lines are dense).
* **ja (reuse: 55):** Receives connection from "a". Sends connections to: ohju, uja, idae, eja, and others.
* **ohju:** Connected from "ja".
* **uja:** Connected from "ja".
* **idae:** Connected from "ja".
* **eja:** Connected from "ja".
* **ista (reuse: 23):** Located at the bottom of the right cluster. Receives connections from multiple sources within the cluster.
* **star:** Connected from an unseen source within the cluster.
* **taide:** Connected from an unseen source within the cluster.
* **vuode:** Connected from an unseen source within the cluster.
* **okuvi:** Connected from an unseen source within the cluster.
### Key Observations
1. **Linguistic Clustering:** The diagram shows a clear separation between a Cyrillic-based lexicon (left) and a Latin-based lexicon (right), bridged by a single node ("україн").
2. **Hub Nodes:** Three nodes are explicitly marked with "reuse" counts, indicating their high frequency or centrality:
* `a (reuse: 167)` - The most prominent hub, located in the right cluster.
* `ja (reuse: 55)` - A secondary hub, directly connected from `a`.
* `ista (reuse: 23)` - A tertiary hub, located at the bottom of the right cluster.
* `чи (reuse: 17)` - The primary hub for the left cluster.
3. **Connection Density:** The area around the `a` and `ja` nodes is extremely dense with connections, suggesting a highly interconnected semantic field. The left cluster around `чи` is also dense but appears slightly more structured.
4. **Directionality:** All connections are directed, implying a one-way relationship (e.g., "is a type of", "leads to", "is translated as", "is derived from").
5. **Isolated Nodes:** Several nodes in both clusters (e.g., `твор`, `star`, `taide`) have incoming lines from outside the visible frame, indicating the diagram is a cropped section of a larger network.
### Interpretation
This diagram is a visualization of a **semantic network or lexical graph**, likely generated from a text corpus analysis. The "reuse" count probably signifies the frequency of that word's appearance as a node in the graph or its degree of connectivity.
* **What it demonstrates:** It maps relationships between words. The central bridge node "україн" (Ukrainian) suggests the graph might be modeling connections between Ukrainian vocabulary and vocabulary from another language (possibly Finnish, given terms like "taide" (art) and "vuode" (bed)). The high reuse of the node "a" is intriguing; in Finnish, "a" is not a common standalone word, so it might represent a root, a morpheme, or a placeholder in the analysis.
* **Relationships:** The arrows likely represent a specific linguistic relationship defined by the analysis tool, such as synonymy, hypernymy, translation equivalence, or co-occurrence. The dense clusters represent tightly-knit semantic fields.
* **Anomalies/Notable Points:** The stark linguistic divide is the most striking feature. The diagram seems to model a cross-lingual or comparative linguistic structure. The node "а" (Cyrillic 'a') is not present, but the Latin "a" is a major hub, which could be a point of interest for the researcher. The diagram's cropped nature means the full context of the relationships for nodes like `твор` or `star` is missing.
**In summary, this is a technical visualization from a computational linguistics or natural language processing study, showing a directed graph of word relationships across two languages, with key hub nodes identified by their reuse frequency.**
DECODING INTELLIGENCE...