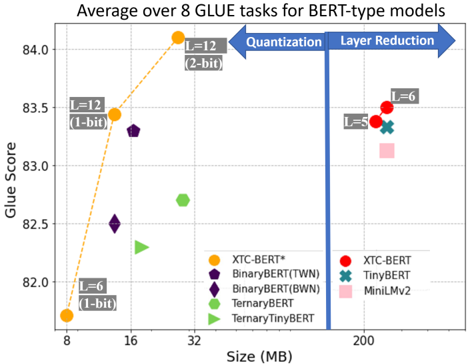
## Scatter Chart: Average GLUE Score vs. Model Size for BERT-type Models
### Overview
The image is a scatter plot comparing the size (in MB) of various BERT-type models against their average GLUE score (a measure of language understanding performance). The plot highlights the impact of quantization and layer reduction techniques on model size and performance.
### Components/Axes
* **Title:** Average over 8 GLUE tasks for BERT-type models
* **X-axis:** Size (MB). Scale: 8, 16, 32, 200
* **Y-axis:** Glue Score. Scale: 82.0, 82.5, 83.0, 83.5, 84.0
* **Legend:** Located in the bottom-left and bottom-right of the chart.
* **XTC-BERT*:** Orange circle
* **BinaryBERT(TWN):** Purple pentagon
* **BinaryBERT(BWN):** Purple diamond
* **TernaryBERT:** Green triangle pointing right
* **TernaryTinyBERT:** Green triangle pointing left
* **XTC-BERT:** Red circle
* **TinyBERT:** Teal X
* **MiniLMv2:** Pink square
* **Annotations:**
* "L=12 (1-bit)" near the orange XTC-BERT* data point at approximately (12, 83.5)
* "L=6 (1-bit)" near the orange XTC-BERT* data point at approximately (8, 81.8)
* "L=12 (2-bit)" near the orange XTC-BERT* data point at approximately (28, 84.1)
* "L=6" near the red XTC-BERT data point at approximately (200, 83.5)
* "L=5" near the red XTC-BERT data point at approximately (200, 83.3)
* **Vertical Blue Bar:** Separates "Quantization" (left) from "Layer Reduction" (right).
* **Dashed Orange Line:** Connects the XTC-BERT* data points.
### Detailed Analysis
* **XTC-BERT* (Orange Circles):**
* Trend: As size increases, Glue Score increases.
* Data Points:
* (8, approximately 81.8), labeled "L=6 (1-bit)"
* (approximately 12, approximately 83.5), labeled "L=12 (1-bit)"
* (approximately 28, approximately 84.1), labeled "L=12 (2-bit)"
* **BinaryBERT(TWN) (Purple Pentagons):**
* Data Point: (approximately 16, approximately 83.3)
* **BinaryBERT(BWN) (Purple Diamonds):**
* Data Point: (approximately 16, approximately 82.5)
* **TernaryBERT (Green Triangles pointing right):**
* Data Point: (approximately 32, approximately 82.7)
* **TernaryTinyBERT (Green Triangles pointing left):**
* Data Point: (approximately 16, approximately 82.3)
* **XTC-BERT (Red Circles):**
* Data Point: (approximately 200, approximately 83.5), labeled "L=6"
* Data Point: (approximately 200, approximately 83.3), labeled "L=5"
* **TinyBERT (Teal X):**
* Data Point: (approximately 200, approximately 83.3)
* **MiniLMv2 (Pink Square):**
* Data Point: (approximately 200, approximately 83.1)
### Key Observations
* The XTC-BERT* model shows a clear improvement in Glue Score as size increases with quantization.
* Layer reduction techniques (right side of the plot) generally result in larger models (200 MB) but varying Glue Scores.
* The vertical blue bar visually separates the impact of quantization (left) from layer reduction (right).
### Interpretation
The chart suggests that quantization can effectively reduce model size while maintaining or even improving performance, as seen with the XTC-BERT* model. However, layer reduction, while resulting in larger models, does not guarantee a higher Glue Score, indicating a trade-off between model size and performance. The different models employing layer reduction techniques cluster around the 200 MB size, but their performance varies, suggesting that the specific layer reduction strategy significantly impacts the final Glue Score. The XTC-BERT model appears in both the quantization and layer reduction sections, suggesting it was used as a baseline for both sets of experiments.