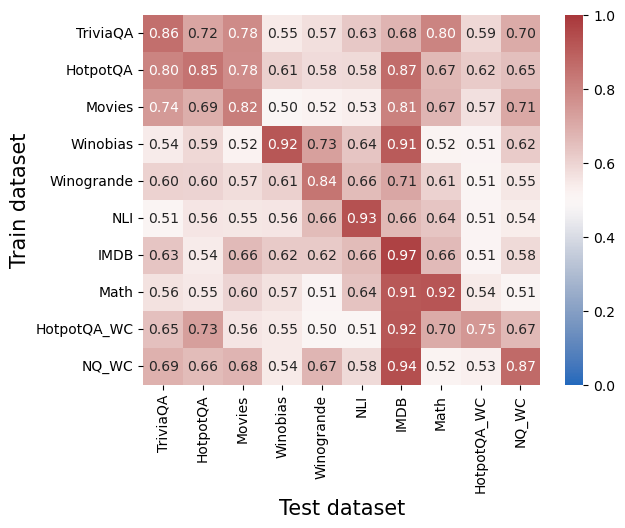
## Heatmap: Correlation Between Training and Test Datasets
### Overview
This heatmap visualizes the correlation strength between different training and test datasets for question-answering models. Values range from 0.0 (no correlation, blue) to 1.0 (perfect correlation, red). The matrix reveals how well models trained on specific datasets perform on various test datasets.
### Components/Axes
- **X-axis (Test dataset)**: TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA_WC, NQ_WC
- **Y-axis (Train dataset)**: Same categories as X-axis
- **Color legend**: Blue (0.0) to Red (1.0), with intermediate shades representing incremental correlation strength
### Detailed Analysis
- **Diagonal values** (self-correlation):
- TriviaQA: 0.86
- HotpotQA: 0.80
- Movies: 0.74
- Winobias: 0.92
- Winogrande: 0.60
- NLI: 0.51
- IMDB: 0.63
- Math: 0.56
- HotpotQA_WC: 0.65
- NQ_WC: 0.69
- **Notable cross-dataset correlations**:
- **IMDB** (train) vs. **NLI** (test): 0.93
- **IMDB** (train) vs. **IMDB** (test): 0.97
- **HotpotQA_WC** (train) vs. **NQ_WC** (test): 0.87
- **Winobias** (train) vs. **Winobias** (test): 0.92
- **Math** (train) vs. **Math** (test): 0.92
- **Lowest correlations**:
- **Winobias** (train) vs. **Winogrande** (test): 0.57
- **Math** (train) vs. **Winobias** (test): 0.52
- **NLI** (train) vs. **TriviaQA** (test): 0.51
### Key Observations
1. **Self-correlation dominance**: All diagonal values exceed 0.5, indicating models retain strong performance on their training datasets.
2. **IMDB and NLI synergy**: High cross-correlation (0.93) suggests shared linguistic patterns or question structures.
3. **WC variants**: HotpotQA_WC and NQ_WC show moderate self-correlation (0.65–0.69) but strong mutual correlation (0.87).
4. **Math dataset**: High self-correlation (0.92) but poor transfer to Winobias (0.52), indicating domain specificity.
5. **Winobias/Winogrande**: Low mutual correlation (0.57) despite similar naming conventions, suggesting divergent task requirements.
### Interpretation
The heatmap demonstrates that **domain-specific training** (e.g., IMDB, Math) yields high performance on matching test sets but limited transferability to dissimilar datasets. **IMDB and NLI** exhibit exceptional cross-dataset compatibility, likely due to overlapping question types (e.g., factoid QA). The **WC variants** (HotpotQA_WC, NQ_WC) show moderate self-performance but strong mutual correlation, implying shared contextual features.
Models trained on **Winobias** or **Winogrande** struggle with cross-dataset generalization, highlighting their specialized nature. The **Math dataset**'s high self-correlation but poor transfer to Winobias underscores its narrow focus on numerical reasoning.
This analysis suggests that dataset selection for training should balance domain specificity (for targeted tasks) and generalizability (for broad applicability), with IMDB and NLI being optimal for cross-dataset performance.