## Diagram: Model Training Flow
### Overview
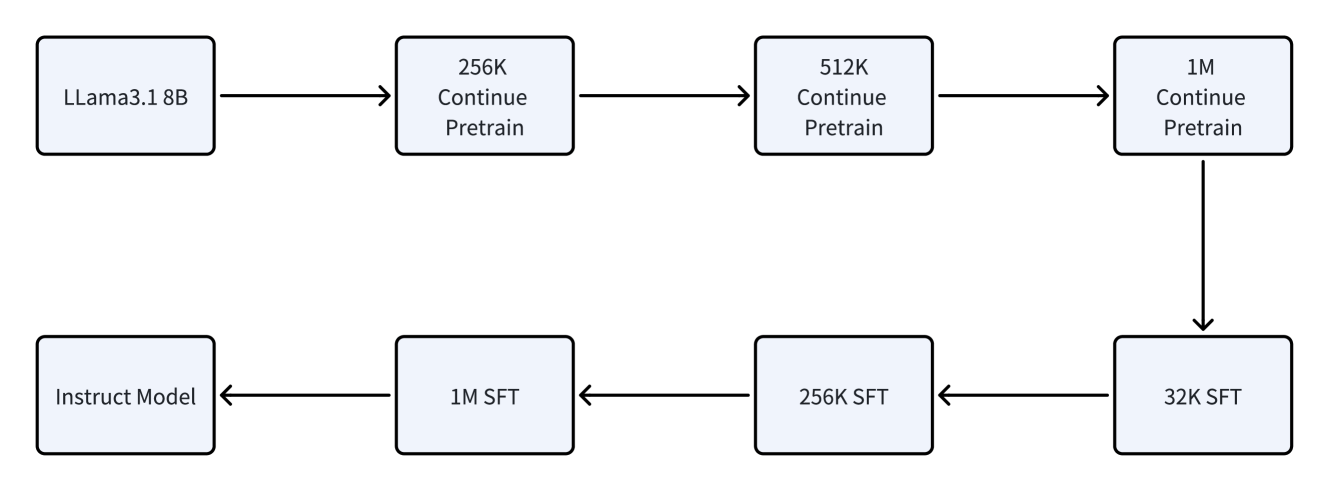
The image is a flowchart illustrating the training process of a model, starting with "LLama3.1 8B" and progressing through several stages of "Continue Pretrain" and "SFT" (Supervised Fine-Tuning) before resulting in an "Instruct Model".
### Components/Axes
The diagram consists of rectangular boxes representing different stages of model training, connected by arrows indicating the flow of the process. The stages are:
* **LLama3.1 8B**: Initial model.
* **256K Continue Pretrain**: Continue pretraining with 256K data.
* **512K Continue Pretrain**: Continue pretraining with 512K data.
* **1M Continue Pretrain**: Continue pretraining with 1M data.
* **32K SFT**: Supervised Fine-Tuning with 32K data.
* **256K SFT**: Supervised Fine-Tuning with 256K data.
* **1M SFT**: Supervised Fine-Tuning with 1M data.
* **Instruct Model**: Final instructed model.
### Detailed Analysis or Content Details
The flow starts with "LLama3.1 8B", then proceeds through "256K Continue Pretrain", "512K Continue Pretrain", and "1M Continue Pretrain" in sequence. From "1M Continue Pretrain", the flow branches down to "32K SFT". The flow then continues from "32K SFT" to "256K SFT", then to "1M SFT", and finally to "Instruct Model".
### Key Observations
* The diagram shows a sequential process of pretraining and fine-tuning.
* The pretraining phase increases in data size (256K -> 512K -> 1M).
* The fine-tuning phase decreases in data size (1M -> 256K -> 32K).
* The "1M Continue Pretrain" stage is a branching point, leading to the fine-tuning stages.
### Interpretation
The diagram illustrates a common strategy in machine learning where a model is first pretrained on a large dataset and then fine-tuned on a smaller, task-specific dataset. The initial pretraining stages likely aim to learn general language representations, while the subsequent fine-tuning stages adapt the model to a specific instruction-following task. The decreasing data size in the fine-tuning stages might reflect a focus on high-quality, curated data for instruction tuning. The branching from "1M Continue Pretrain" suggests that the model's weights after this stage are used as a starting point for the supervised fine-tuning process.