\n
## Diagram: Model Training Pipeline
### Overview
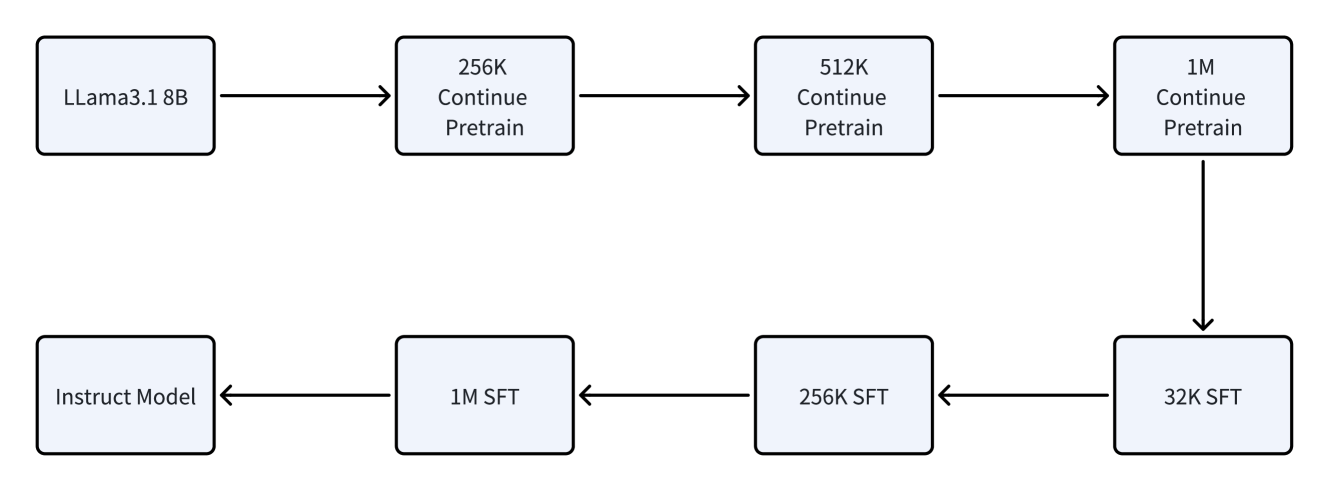
The image depicts a diagram illustrating a model training pipeline, starting with a base model (Llama3.1 8B) and progressing through stages of continued pretraining and supervised fine-tuning (SFT) to arrive at an Instruct Model. The diagram shows a two-branch flow, one for pretraining and one for fine-tuning, converging at the Instruct Model.
### Components/Axes
The diagram consists of rectangular boxes representing different model stages, connected by arrows indicating the flow of data/training. The boxes contain text labels describing the model and training process. There are no axes or scales present.
### Detailed Analysis or Content Details
The diagram can be broken down into two main paths:
**Top Path (Pretraining):**
1. **Llama3.1 8B:** The starting point, a base language model.
2. **256K Continue Pretrain:** The model is further pretrained with a dataset of 256K tokens.
3. **512K Continue Pretrain:** The model is further pretrained with a dataset of 512K tokens.
4. **1M Continue Pretrain:** The model is further pretrained with a dataset of 1M tokens.
**Bottom Path (Supervised Fine-tuning - SFT):**
1. **Instruct Model:** The final output, an instruction-following model.
2. **1M SFT:** The model is fine-tuned using supervised learning with a dataset of 1M tokens.
3. **256K SFT:** The model is fine-tuned using supervised learning with a dataset of 256K tokens.
4. **32K SFT:** The model is fine-tuned using supervised learning with a dataset of 32K tokens.
The arrows indicate a sequential flow. The top path flows from Llama3.1 8B through increasing token counts for continued pretraining. The bottom path flows from the Instruct Model through decreasing token counts for SFT. The two paths converge on the Instruct Model.
### Key Observations
The diagram highlights a progressive training strategy. The model is first pretrained on larger datasets (256K, 512K, 1M tokens) and then fine-tuned on smaller, instruction-specific datasets (32K, 256K, 1M tokens). The decreasing token counts in the SFT path suggest a refinement process, where the model is gradually adjusted to follow instructions.
### Interpretation
This diagram illustrates a common approach to training large language models. The initial pretraining phase aims to equip the model with general language understanding capabilities. The subsequent fine-tuning phase specializes the model for specific tasks, in this case, following instructions. The use of different token counts suggests a deliberate strategy for balancing general knowledge with task-specific expertise. The two-branch structure emphasizes the separation of concerns between pretraining and fine-tuning, allowing for independent optimization of each stage. The diagram suggests a pipeline where the output of the pretraining stage serves as the input to the fine-tuning stage. The choice of token counts (32K, 256K, 1M) likely reflects a trade-off between computational cost and model performance.