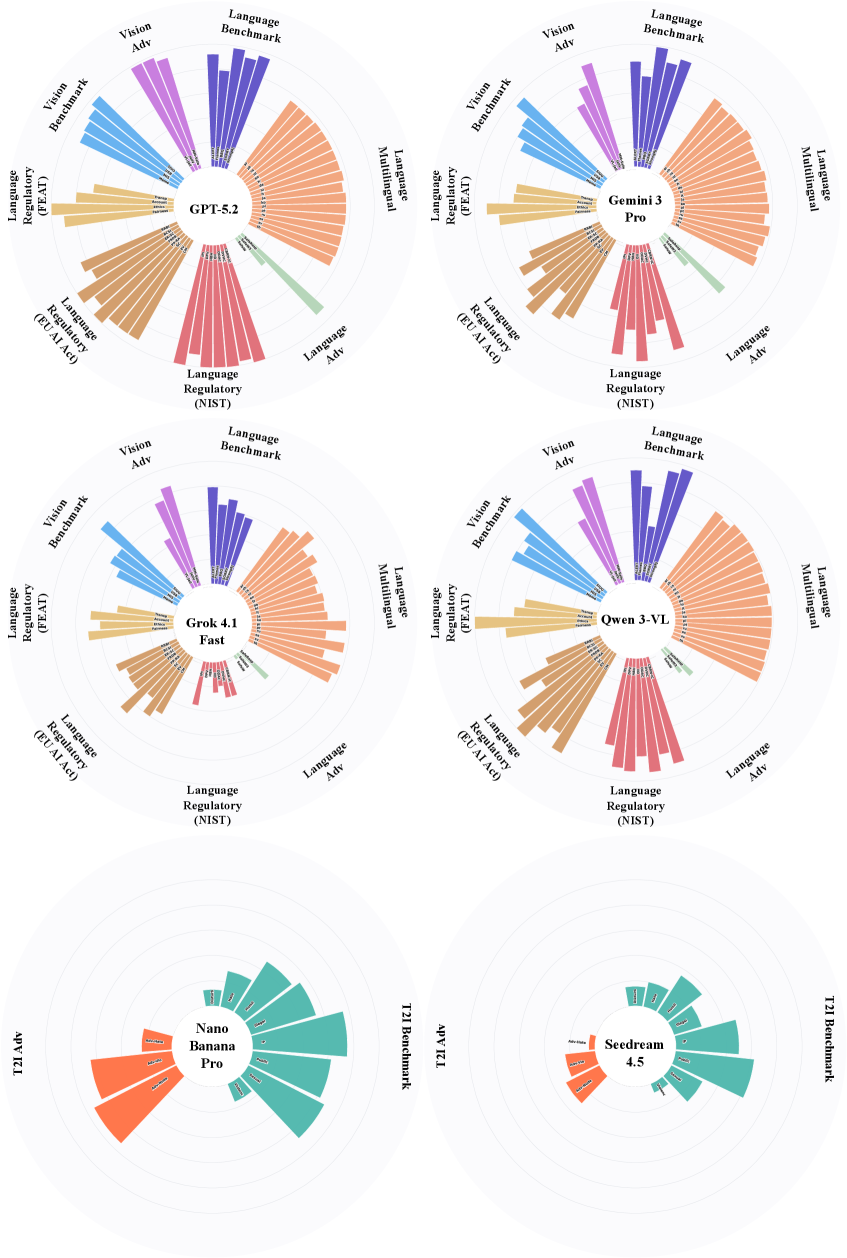
# Technical Data Extraction: AI Model Performance Comparison
This document provides a comprehensive extraction of data from a set of six circular bar charts (radial plots) comparing the performance of various Large Language Models (LLMs) across multiple evaluation categories.
## 1. Document Structure
The image contains six independent radial charts arranged in a 3x2 grid. The top four charts share a common schema of 8 evaluation categories, while the bottom two charts use a different schema of 2 evaluation categories.
---
## 2. Primary Model Comparison (Top 4 Charts)
**Models:** GPT-5.2, Gemini 3 Pro, Grok 4.1 Fast, Qwen 3-VL.
### Shared Schema (Categories and Sub-metrics)
The charts are divided into 8 color-coded segments. Each segment contains individual bars representing specific benchmarks. The radial axis represents a scale (0 to 100, implied by the concentric rings).
| Category Label | Color | Sub-metrics / Labels (Clockwise) |
| :--- | :--- | :--- |
| **Language Benchmark** | Dark Purple | MMLU, GSM8K, HumanEval, MBPP, ARC-C |
| **Language Multilingual** | Light Orange | MGSM, XCOPA, TyDiQA, Flores-101 (multiple bars) |
| **Language Adv** | Light Green | Adv-GLUE, Adv-SQuAD |
| **Language Regulatory (NIST)** | Red/Pink | NIST-1, NIST-2, NIST-3, NIST-4, NIST-5, NIST-6 |
| **Language Regulatory (EU AI Act)** | Brown | Art-10, Art-13, Art-14, Art-15, Art-28, Art-52 |
| **Language Regulatory (FEAT)** | Gold | Transp., Account., Ethics, Fairness |
| **Vision Benchmark** | Light Blue | MMMU, VQAv2, TextVQA, ChartQA, DocVQA |
| **Vision Adv** | Lavender | Adv-MMMU, Adv-VQAv2, Adv-TextVQA |
### Comparative Performance Analysis
* **GPT-5.2:** Shows the most balanced and "full" profile. It dominates in **Language Benchmark** and **Language Multilingual** categories. Its **Vision Benchmark** performance is consistently high across all sub-metrics.
* **Gemini 3 Pro:** Exhibits very strong performance in **Language Benchmark** and **Vision Benchmark**, nearly matching GPT-5.2. It shows slightly lower scores in the **Language Regulatory (EU AI Act)** brown segment compared to GPT-5.2.
* **Grok 4.1 Fast:** Shows significant variance. While strong in **Language Benchmark**, it has noticeable "gaps" or shorter bars in the **Language Multilingual** and **Language Regulatory (NIST)** sections compared to the top two models.
* **Qwen 3-VL:** Displays a strong profile in **Vision Benchmark** (blue) and **Language Multilingual** (orange), but shows lower performance in the **Language Regulatory (FEAT)** (gold) and **Vision Adv** (lavender) categories.
---
## 3. Specialized Model Comparison (Bottom 2 Charts)
**Models:** Nano Banana Pro, Seedream 4.5.
### Shared Schema
These models are evaluated on a simplified two-category schema.
| Category Label | Color | Sub-metrics / Labels |
| :--- | :--- | :--- |
| **T2I Benchmark** | Teal | HEVAL, VQAScore, GenEval, DPG-Bench, T2I-CompBench |
| **T2I Adv** | Orange | Adv-Halo, Adv-Stat, Adv-Rel, Adv-Multi |
### Comparative Performance Analysis
* **Nano Banana Pro:**
* **T2I Benchmark (Teal):** Shows high performance in the outer bars (DPG-Bench and T2I-CompBench) but lower scores in the inner benchmarks (HEVAL).
* **T2I Adv (Orange):** Shows a strong upward trend in adversarial robustness, with the "Adv-Multi" bar reaching the furthest outer ring.
* **Seedream 4.5:**
* **T2I Benchmark (Teal):** Generally lower performance across all teal metrics compared to Nano Banana Pro. The bars are significantly shorter, indicating lower benchmark scores.
* **T2I Adv (Orange):** Very low performance in adversarial metrics. The bars barely extend past the first two concentric rings, indicating vulnerability or poor performance in adversarial Text-to-Image tasks.
---
## 4. Spatial and Visual Metadata
* **Legend Placement:** Labels are placed peripherally around the circular plots.
* **Scale:** Each chart contains 5 concentric grey rings, likely representing 20% increments (20, 40, 60, 80, 100).
* **Language:** All text is in **English**.
* **Data Trends:** In the top four models, the "Language Benchmark" (Purple) consistently shows the highest values (bars reaching the outermost ring), while "Language Adv" (Green) consistently shows the lowest values across all models, indicating a general industry weakness in adversarial language tasks.