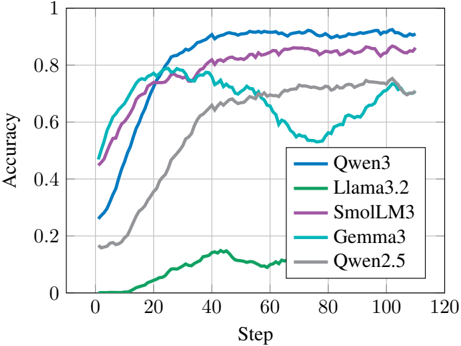
\n
## Line Chart: Model Accuracy vs. Training Step
### Overview
This image presents a line chart illustrating the accuracy of five different language models (Qwen3, Llama3.2, SmolLM3, Gemma3, and Qwen2.5) as a function of training step. The chart visually tracks the learning progress of each model, showing how their accuracy changes over the course of approximately 120 training steps.
### Components/Axes
* **X-axis:** Labeled "Step", ranging from 0 to 120. Represents the progression of training.
* **Y-axis:** Labeled "Accuracy", ranging from 0 to 1. Represents the performance of the models.
* **Legend:** Located in the top-right corner of the chart. It maps colors to the following models:
* Blue: Qwen3
* Green: Llama3.2
* Purple: SmolLM3
* Cyan: Gemma3
* Gray: Qwen2.5
### Detailed Analysis
Here's a breakdown of each model's accuracy trend and approximate data points:
* **Qwen3 (Blue):** The line slopes upward rapidly from step 0, reaching approximately 0.5 accuracy at step 10. It continues to increase, plateauing around 0.9 accuracy between steps 40 and 100. There's a slight dip around step 60, falling to approximately 0.85, before recovering.
* Step 0: ~0.15
* Step 10: ~0.5
* Step 20: ~0.7
* Step 40: ~0.85
* Step 60: ~0.85
* Step 80: ~0.9
* Step 100: ~0.9
* Step 120: ~0.9
* **Llama3.2 (Green):** This line starts at approximately 0 accuracy and increases slowly until step 40, reaching around 0.2 accuracy. It then shows a more rapid increase, reaching approximately 0.3 accuracy at step 60. The line plateaus around 0.3 accuracy after step 60.
* Step 0: ~0
* Step 10: ~0.02
* Step 20: ~0.1
* Step 40: ~0.2
* Step 60: ~0.3
* Step 80: ~0.3
* Step 100: ~0.3
* Step 120: ~0.3
* **SmolLM3 (Purple):** The line increases rapidly from step 0, reaching approximately 0.5 accuracy at step 10. It continues to increase, reaching approximately 0.8 accuracy at step 20 and plateauing around 0.85-0.9 accuracy from step 40 onwards.
* Step 0: ~0.1
* Step 10: ~0.5
* Step 20: ~0.8
* Step 40: ~0.85
* Step 60: ~0.88
* Step 80: ~0.9
* Step 100: ~0.9
* Step 120: ~0.9
* **Gemma3 (Cyan):** The line starts with a rapid increase from step 0, reaching approximately 0.5 accuracy at step 10. It continues to increase, reaching approximately 0.75 accuracy at step 20. Around step 50, the line peaks at approximately 0.85 accuracy, then declines sharply to around 0.6 accuracy at step 60, and then plateaus around 0.6-0.7.
* Step 0: ~0.1
* Step 10: ~0.5
* Step 20: ~0.75
* Step 40: ~0.8
* Step 50: ~0.85
* Step 60: ~0.6
* Step 80: ~0.65
* Step 100: ~0.65
* Step 120: ~0.65
* **Qwen2.5 (Gray):** The line increases slowly from step 0, reaching approximately 0.2 accuracy at step 20. It continues to increase, reaching approximately 0.6 accuracy at step 60, and then plateaus around 0.65-0.7 accuracy.
* Step 0: ~0.15
* Step 10: ~0.2
* Step 20: ~0.3
* Step 40: ~0.5
* Step 60: ~0.6
* Step 80: ~0.65
* Step 100: ~0.65
* Step 120: ~0.7
### Key Observations
* Qwen3 and SmolLM3 achieve the highest accuracy, both reaching approximately 0.9.
* Gemma3 exhibits a significant drop in accuracy after reaching its peak around step 50, suggesting potential overfitting or instability.
* Llama3.2 demonstrates the slowest learning rate and lowest overall accuracy.
* Qwen2.5 shows a steady but moderate improvement in accuracy.
### Interpretation
The chart demonstrates the learning curves of five different language models during training. The varying slopes and final accuracy levels indicate differences in model capacity, training efficiency, and potential for overfitting. Qwen3 and SmolLM3 appear to be the most effective models in this comparison, achieving high accuracy relatively quickly. Gemma3's initial success followed by a decline suggests that it may require further regularization or adjustments to its training process. Llama3.2's slow progress indicates that it may benefit from a larger model size, different architecture, or a longer training duration. The data suggests that the choice of model significantly impacts performance, and careful consideration should be given to the specific requirements of the task when selecting a language model. The anomaly of Gemma3's accuracy drop warrants further investigation to understand the underlying cause and potential mitigation strategies.