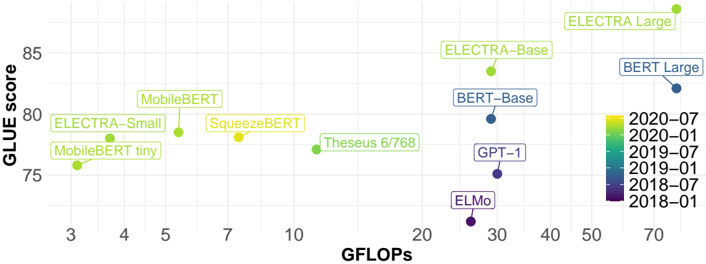
## Scatter Plot: GLUE Score vs. GFLOPs for NLP Models
### Overview
The image is a scatter plot comparing the performance (GLUE score) of various natural language processing (NLP) models against their computational cost (GFLOPs). Models are color-coded by release date, with a legend indicating temporal progression from 2018 to 2020.
### Components/Axes
- **X-axis (GFLOPs)**: Ranges from 3 to 70, labeled "GFLOPs" in bold black text.
- **Y-axis (GLUE score)**: Ranges from 75 to 85, labeled "GLUE score" in bold black text.
- **Legend**: Vertical color gradient on the right, with dates (2018-01 to 2020-07) and corresponding colors (purple to yellow). Each model is annotated with its name and release date.
- **Data Points**: Labeled with model names (e.g., "ELECTRA-Large," "BERT-Large") and positioned according to their GFLOPs and GLUE scores.
### Detailed Analysis
1. **ELECTRA-Large** (2020-07, yellow):
- GFLOPs: ~70
- GLUE score: ~88
- Position: Top-right corner, highest GFLOPs and GLUE score.
2. **BERT-Large** (2018-01, dark blue):
- GFLOPs: ~50
- GLUE score: ~82
- Position: Mid-right, second-highest GLUE score.
3. **ELECTRA-Base** (2020-01, light green):
- GFLOPs: ~20
- GLUE score: ~83
- Position: Mid-right, third-highest GLUE score.
4. **MobileBERT** (2020-01, light green):
- GFLOPs: ~5
- GLUE score: ~79
- Position: Mid-left, moderate performance.
5. **SqueezeBERT** (2020-01, light green):
- GFLOPs: ~7
- GLUE score: ~78
- Position: Mid-left, lower than MobileBERT.
6. **MobileBERT tiny** (2020-01, light green):
- GFLOPs: ~3
- GLUE score: ~76
- Position: Bottom-left, lowest GFLOPs and score.
7. **Theseus 6/768** (2020-01, light green):
- GFLOPs: ~10
- GLUE score: ~77
- Position: Mid-left, slightly better than SqueezeBERT.
8. **GPT-1** (2018-01, purple):
- GFLOPs: ~30
- GLUE score: ~75
- Position: Mid-right, low score despite high GFLOPs.
9. **ELMo** (2018-01, purple):
- GFLOPs: ~25
- GLUE score: ~74
- Position: Bottom-left, lowest score overall.
### Key Observations
- **Temporal Trend**: Newer models (2020) generally achieve higher GLUE scores but require more GFLOPs.
- **Efficiency Outliers**:
- **SqueezeBERT** (2020-01) achieves a GLUE score of ~78 with only ~7 GFLOPs, outperforming older models like GPT-1 (30 GFLOPs, 75 score).
- **ELMo** (2018-01) has the lowest score (~74) despite moderate GFLOPs (~25).
- **Performance vs. Cost**: ELECTRA-Large (70 GFLOPs, 88 score) dominates in both metrics, while MobileBERT tiny (3 GFLOPs, 76 score) shows minimal computational cost but limited performance.
### Interpretation
The plot highlights a trade-off between model size (GFLOPs) and performance (GLUE score). Newer models (2020) like ELECTRA-Large and BERT-Large achieve state-of-the-art results but demand significantly more computational resources. However, some 2020 models (e.g., SqueezeBERT) demonstrate efficiency by balancing performance and cost. Older models like ELMo and GPT-1 lag in performance despite higher GFLOPs, suggesting architectural improvements in newer designs. This underscores the importance of optimizing model efficiency alongside performance in NLP development.