\n
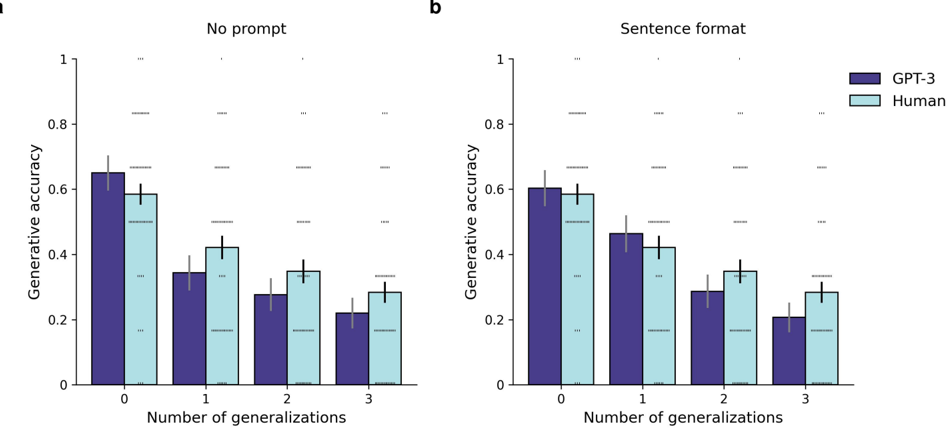
## Bar Charts: Generative Accuracy vs. Number of Generalizations
### Overview
The image presents two bar charts (labeled 'a' and 'b') comparing the generative accuracy of GPT-3 and humans across different numbers of generalizations. Chart 'a' shows results "No prompt" while chart 'b' shows results with "Sentence format". Both charts use the same x-axis (Number of generalizations) and y-axis (Generative accuracy). Error bars are present on each bar, indicating variability.
### Components/Axes
* **X-axis:** "Number of generalizations" with markers at 0, 1, 2, and 3.
* **Y-axis:** "Generative accuracy" with a scale ranging from 0 to 1.
* **Legend:**
* Dark Purple: GPT-3
* Light Blue: Human
* **Titles:**
* Chart a: "No prompt" (top-left)
* Chart b: "Sentence format" (top-left)
### Detailed Analysis or Content Details
**Chart a: No prompt**
* **GPT-3 (Dark Purple):**
* 0 Generalizations: Approximately 0.32, with an error bar extending from roughly 0.22 to 0.42.
* 1 Generalization: Approximately 0.36, with an error bar extending from roughly 0.26 to 0.46.
* 2 Generalizations: Approximately 0.28, with an error bar extending from roughly 0.18 to 0.38.
* 3 Generalizations: Approximately 0.24, with an error bar extending from roughly 0.14 to 0.34.
* Trend: The GPT-3 accuracy initially increases slightly from 0 to 1 generalization, then decreases steadily from 1 to 3 generalizations.
* **Human (Light Blue):**
* 0 Generalizations: Approximately 0.58, with an error bar extending from roughly 0.48 to 0.68.
* 1 Generalization: Approximately 0.42, with an error bar extending from roughly 0.32 to 0.52.
* 2 Generalizations: Approximately 0.32, with an error bar extending from roughly 0.22 to 0.42.
* 3 Generalizations: Approximately 0.28, with an error bar extending from roughly 0.18 to 0.38.
* Trend: Human accuracy decreases steadily from 0 to 3 generalizations.
**Chart b: Sentence format**
* **GPT-3 (Dark Purple):**
* 0 Generalizations: Approximately 0.44, with an error bar extending from roughly 0.34 to 0.54.
* 1 Generalization: Approximately 0.40, with an error bar extending from roughly 0.30 to 0.50.
* 2 Generalizations: Approximately 0.28, with an error bar extending from roughly 0.18 to 0.38.
* 3 Generalizations: Approximately 0.24, with an error bar extending from roughly 0.14 to 0.34.
* Trend: GPT-3 accuracy decreases steadily from 0 to 3 generalizations.
* **Human (Light Blue):**
* 0 Generalizations: Approximately 0.62, with an error bar extending from roughly 0.52 to 0.72.
* 1 Generalization: Approximately 0.38, with an error bar extending from roughly 0.28 to 0.48.
* 2 Generalizations: Approximately 0.30, with an error bar extending from roughly 0.20 to 0.40.
* 3 Generalizations: Approximately 0.26, with an error bar extending from roughly 0.16 to 0.36.
* Trend: Human accuracy decreases steadily from 0 to 3 generalizations.
### Key Observations
* In both charts, human accuracy is generally higher than GPT-3 accuracy at 0 generalizations.
* Both GPT-3 and humans show a decreasing trend in generative accuracy as the number of generalizations increases.
* The error bars indicate substantial variability in the data, making precise comparisons challenging.
* The "Sentence format" prompt (Chart b) appears to slightly improve GPT-3's accuracy at 0 and 1 generalizations compared to "No prompt" (Chart a).
### Interpretation
The data suggests that both GPT-3 and humans struggle with generative tasks as the complexity (measured by the number of generalizations) increases. Humans consistently outperform GPT-3, particularly when no prompt is provided. The slight improvement in GPT-3's performance with the "Sentence format" prompt suggests that providing some contextual guidance can be beneficial. The decreasing accuracy with increasing generalizations could indicate a limitation in the models' ability to maintain coherence and relevance as the task becomes more abstract. The large error bars suggest that individual performance varies significantly, and the observed differences may not be statistically significant without further analysis. The charts demonstrate a trade-off between simplicity and accuracy in generative tasks, with simpler tasks (fewer generalizations) yielding higher accuracy for both models.