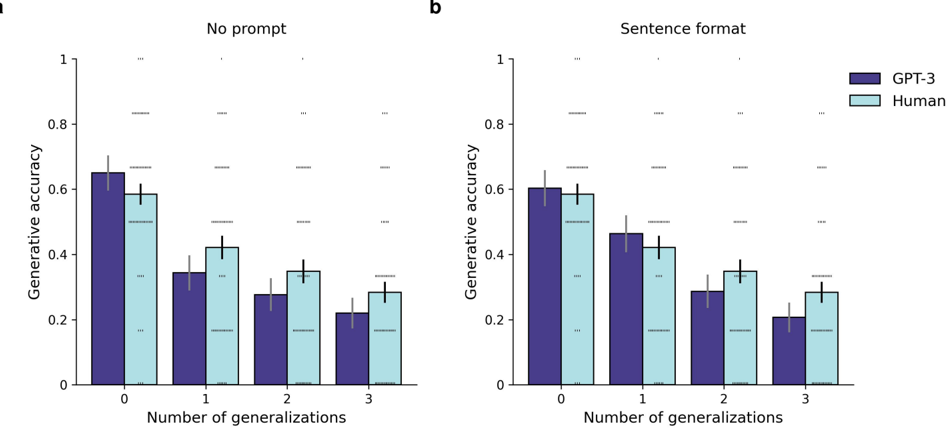
## Bar Charts: Generative Accuracy vs. Number of Generalizations
### Overview
Two bar charts compare generative accuracy between GPT-3 (purple) and humans (light blue) across two conditions: "No prompt" (Chart a) and "Sentence format" (Chart b). The x-axis represents the number of generalizations (0–3), and the y-axis represents generative accuracy (0–1). Error bars indicate variability (±0.05–0.1).
### Components/Axes
- **X-axis**: "Number of generalizations" (0, 1, 2, 3).
- **Y-axis**: "Generative accuracy" (0–1, increments of 0.2).
- **Legends**:
- Purple = GPT-3
- Light blue = Human
- **Chart Titles**:
- Chart a: "No prompt"
- Chart b: "Sentence format"
### Detailed Analysis
#### Chart a ("No prompt")
- **GPT-3**:
- 0 generalizations: ~0.65 (±0.05)
- 1 generalization: ~0.35 (±0.05)
- 2 generalizations: ~0.25 (±0.05)
- 3 generalizations: ~0.2 (±0.05)
- **Human**:
- 0 generalizations: ~0.6 (±0.05)
- 1 generalization: ~0.4 (±0.05)
- 2 generalizations: ~0.35 (±0.05)
- 3 generalizations: ~0.3 (±0.05)
#### Chart b ("Sentence format")
- **GPT-3**:
- 0 generalizations: ~0.6 (±0.05)
- 1 generalization: ~0.45 (±0.05)
- 2 generalizations: ~0.3 (±0.05)
- 3 generalizations: ~0.25 (±0.05)
- **Human**:
- 0 generalizations: ~0.58 (±0.05)
- 1 generalization: ~0.42 (±0.05)
- 2 generalizations: ~0.35 (±0.05)
- 3 generalizations: ~0.3 (±0.05)
### Key Observations
1. **Declining Accuracy with Generalizations**:
- Both GPT-3 and humans show reduced accuracy as the number of generalizations increases.
- GPT-3’s accuracy drops more sharply than humans in "No prompt" (Chart a).
- In "Sentence format" (Chart b), the decline is less steep, but GPT-3 still underperforms humans at higher generalization counts.
2. **Initial Performance Gap**:
- At 0 generalizations, GPT-3 slightly outperforms humans in both conditions (~0.65 vs. ~0.6 in Chart a; ~0.6 vs. ~0.58 in Chart b).
3. **Error Bars**:
- Variability is consistent across conditions, with error margins of ±0.05–0.1.
### Interpretation
- **Prompt Impact**: The "Sentence format" (Chart b) mitigates accuracy loss compared to "No prompt" (Chart a), suggesting structured prompts improve model performance.
- **Human vs. Model**: Humans maintain relatively stable accuracy across generalizations, while GPT-3 struggles more with complexity.
- **Model Limitations**: GPT-3’s performance degrades significantly with increased generalizations, highlighting challenges in handling open-ended tasks without explicit constraints.
- **Practical Implications**: Structured prompts ("Sentence format") may help align model outputs with human expectations, but generalization remains a bottleneck for AI systems.
*Note: All values are approximate, derived from bar heights and error bar ranges.*