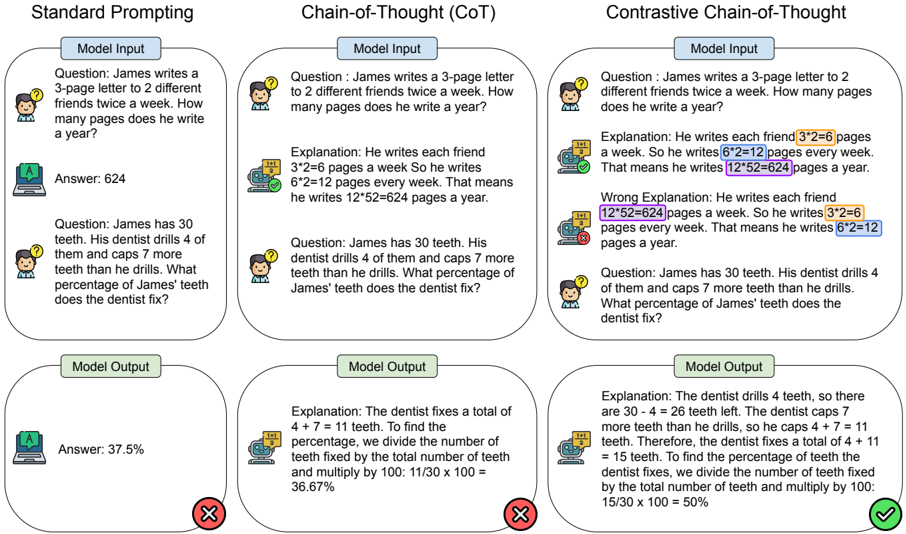
## Comparison of Prompting Techniques: Standard, CoT, and Contrastive CoT
### Overview
The image presents a comparison of three different prompting techniques for Large Language Models (LLMs): Standard Prompting, Chain-of-Thought (CoT) Prompting, and Contrastive Chain-of-Thought (Contrastive CoT) Prompting. Each technique is demonstrated with two example questions, showing the "Model Input", "Explanation" (where applicable), and "Model Output". The results are visually indicated with checkmarks (correct) and crosses (incorrect).
### Components/Axes
The image is divided into three columns, one for each prompting technique. Each column is further divided into two sections, each representing a question-answer pair. Within each section, there are three sub-sections: "Model Input", "Explanation" (for CoT and Contrastive CoT), and "Model Output". Visual cues (checkmarks and crosses) indicate the correctness of the "Model Output".
### Detailed Analysis or Content Details
**Column 1: Standard Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Model Output:** "Answer: 624" (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Model Output:** "Answer: 37.5%" (marked with a checkmark)
**Column 2: Chain-of-Thought (CoT) Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: He writes each friend 3\*2=6 pages a week. So he writes 6\*2=12 pages every week. That means he writes 12\*52=624 pages a year."
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: The dentist fixes a total of 4 + 7 = 11 teeth. To find the percentage, we divide the number of teeth fixed by the total number of teeth and multiply by 100: 11/30 x 100 = 36.67%"
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a cross)
**Column 3: Contrastive Chain-of-Thought (Contrastive CoT) Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: James writes each friend 3\*2=6 pages a week. So he writes 6\*2=12 pages every week. That means he writes 12\*52=624 pages a year. Wrong Explanation: He writes each friend 12\*52=624 pages a week. So he writes 3\*2=6 pages every week. That means he writes 6\*2=12 pages a year."
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: The dentist drills 4 teeth, so there are 30 - 4 = 26 teeth left. The dentist caps 7 more teeth than he drills, so he caps 4 + 7 = 11 teeth. Therefore, the dentist fixes a total of 4 + 11 teeth. To find the percentage of teeth the dentist fixes, we divide the number of teeth fixed by the total number of teeth and multiply by 100: 15/30 x 100 = 50%"
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
### Key Observations
* Standard Prompting and Contrastive CoT both achieve correct answers for both questions.
* CoT Prompting fails on the second question, providing an incorrect percentage (36.67% instead of 50%).
* Contrastive CoT includes a "Wrong Explanation" alongside the correct one, demonstrating the model's ability to identify and contrast incorrect reasoning paths.
* The checkmarks and crosses clearly indicate the success rate of each prompting technique.
### Interpretation
The image demonstrates the effectiveness of different prompting techniques for LLMs. Standard prompting can work well for simple problems, but struggles with more complex reasoning. Chain-of-Thought prompting improves reasoning ability but can still lead to errors, as seen in the second question. Contrastive Chain-of-Thought prompting appears to be the most robust, as it not only provides a correct explanation but also highlights potential pitfalls in reasoning, leading to a higher success rate. The inclusion of a "Wrong Explanation" in Contrastive CoT is a key feature, allowing the model to self-critique and refine its reasoning process. This suggests that explicitly contrasting correct and incorrect reasoning paths can significantly improve the reliability of LLM outputs. The image highlights the importance of prompt engineering in eliciting accurate and reliable responses from LLMs.