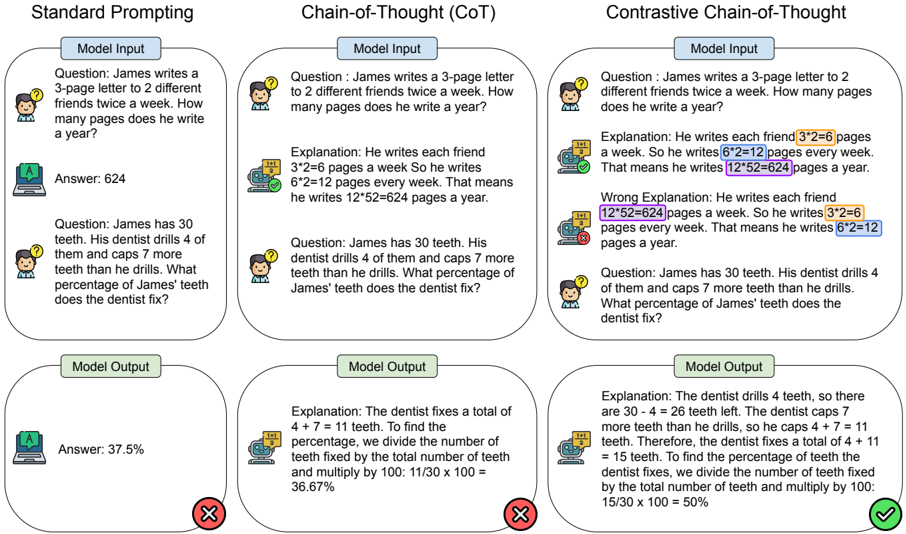
## Screenshot: Comparison of Prompting Methods for Math Problem Solving
### Overview
The image compares three prompting methods for solving math problems: **Standard Prompting**, **Chain-of-Thought (CoT)**, and **Contrastive Chain-of-Thought**. Each method includes a question, model input, explanation, and model output with correctness indicators (✅/❌). The focus is on arithmetic reasoning and percentage calculations.
---
### Components/Axes
- **Columns**: Three vertical sections labeled:
1. **Standard Prompting**
2. **Chain-of-Thought (CoT)**
3. **Contrastive Chain-of-Thought**
- **Rows**: Each column contains:
- **Question**: A math problem (e.g., "James writes a 3-page letter...").
- **Model Input**: The problem statement.
- **Explanation**: Step-by-step reasoning (highlighted in Contrastive CoT).
- **Model Output**: Final answer with correctness feedback (✅/❌).
---
### Detailed Analysis
#### Standard Prompting
- **Question**:
1. James writes a 3-page letter to 2 friends twice a week. How many pages a year?
2. James has 30 teeth. Dentist drills 4, caps 7 more. What percentage fixed?
- **Model Input**: Direct problem statements.
- **Model Output**:
- Answer: 624 (✅).
- Answer: 37.5% (❌).
#### Chain-of-Thought (CoT)
- **Question**: Same as Standard Prompting.
- **Model Input**: Same as Standard Prompting.
- **Explanation**:
1. "He writes each friend 3×2=6 pages a week. So 6×2=12 pages weekly. 12×52=624 yearly."
2. "Dentist fixes 4+7=11 teeth. 11/30×100=36.67%."
- **Model Output**:
- Answer: 624 (✅).
- Answer: 36.67% (❌).
#### Contrastive Chain-of-Thought
- **Question**: Same as Standard Prompting.
- **Model Input**: Same as Standard Prompting.
- **Explanation**:
1. **Correct**: "3×2=6 pages per friend. 6×2=12 weekly. 12×52=624 yearly."
2. **Wrong**: "12×52=624 pages weekly. 3×2=6 pages yearly."
3. **Correct**: "Dentist fixes 4+11=15 teeth. 15/30×100=50%."
- **Model Output**:
- Answer: 624 (✅).
- Answer: 50% (✅).
---
### Key Observations
1. **Standard Prompting** produces correct answers but lacks reasoning transparency.
2. **CoT** improves reasoning clarity but occasionally miscalculates (e.g., 36.67% instead of 50%).
3. **Contrastive CoT** explicitly contrasts correct/incorrect reasoning, leading to accurate answers (50%).
4. **Highlighted Errors**: In Contrastive CoT, incorrect steps (e.g., "12×52=624 pages weekly") are flagged to guide the model.
---
### Interpretation
- **Standard Prompting** is efficient but opaque, risking errors in complex reasoning.
- **CoT** enhances interpretability by breaking down steps but may still propagate mistakes.
- **Contrastive CoT** mitigates errors by contrasting valid/invalid reasoning paths, improving accuracy. This method is particularly effective for percentage calculations, where missteps in intermediate steps (e.g., misapplying multiplication) are critical.
The image demonstrates how structured reasoning (CoT) and error contrast (Contrastive CoT) enhance model performance in mathematical problem-solving.