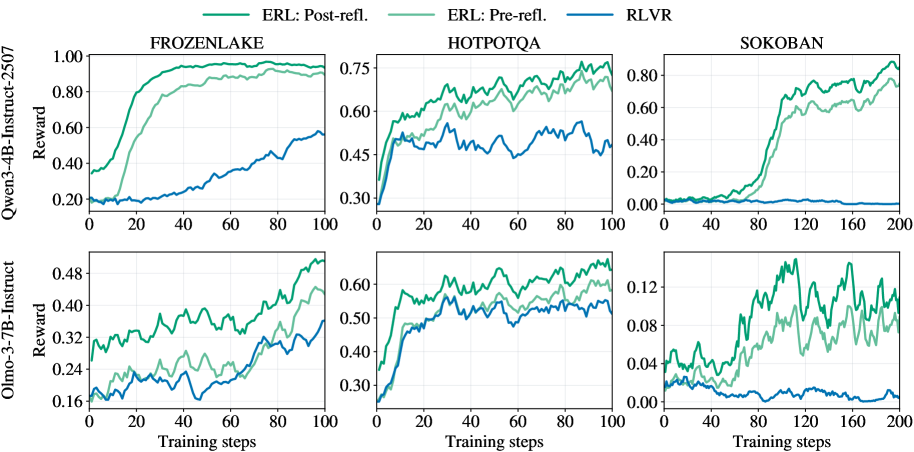
## Chart: Reward vs. Training Steps for Different Models and Environments
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the reward achieved by different models (ERL: Post-refl, ERL: Pre-refl, and RLVR) across varying training steps in different environments (FROZENLAKE, HOTPOTQA, and SOKOBAN). The charts are grouped by the model used (Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct).
### Components/Axes
* **Titles:**
* Top Row (Qwen3-4B-Instruct-2507): FROZENLAKE, HOTPOTQA, SOKOBAN
* Bottom Row (Olmo-3-7B-Instruct): FROZENLAKE, HOTPOTQA, SOKOBAN
* **Y-Axis (Reward):**
* Top Row: Scale from 0.00 to 1.00, with markers at 0.20, 0.40, 0.60, 0.80, and 1.00.
* Top Row (HOTPOTQA): Scale from 0.30 to 0.75, with markers at 0.30, 0.45, 0.60, and 0.75.
* Top Row (SOKOBAN): Scale from 0.00 to 0.80, with markers at 0.00, 0.20, 0.40, 0.60, and 0.80.
* Bottom Row: Scale from 0.16 to 0.48, with markers at 0.16, 0.24, 0.32, 0.40, and 0.48.
* Bottom Row (HOTPOTQA): Scale from 0.30 to 0.60, with markers at 0.30, 0.40, 0.50, and 0.60.
* Bottom Row (SOKOBAN): Scale from 0.00 to 0.12, with markers at 0.00, 0.04, 0.08, and 0.12.
* **X-Axis (Training steps):**
* FROZENLAKE and HOTPOTQA: Scale from 0 to 100, with ticks every 20 steps.
* SOKOBAN: Scale from 0 to 200, with ticks every 40 steps.
* **Labels:**
* Y-Axis Label (left side, vertical): "Reward" for both rows.
* Left of Top Row (vertical): "Qwen3-4B-Instruct-2507"
* Left of Bottom Row (vertical): "Olmo-3-7B-Instruct"
* X-Axis Label (bottom): "Training steps" for all charts.
* **Legend (top):**
* "ERL: Post-refl." (light green line)
* "ERL: Pre-refl." (green line)
* "RLVR" (blue line)
### Detailed Analysis
**Top Row (Qwen3-4B-Instruct-2507):**
* **FROZENLAKE:**
* ERL: Post-refl. (light green): Rapidly increases from ~0.20 to ~0.90 within the first 20 training steps, then plateaus around ~0.95.
* ERL: Pre-refl. (green): Increases from ~0.20 to ~0.80 within the first 20 training steps, then gradually increases to ~0.90, plateauing around ~0.90-0.95.
* RLVR (blue): Starts at ~0.20 and gradually increases to ~0.55 by 100 training steps.
* **HOTPOTQA:**
* ERL: Post-refl. (light green): Starts at ~0.40 and increases to ~0.70 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.45 and increases to ~0.75 with fluctuations.
* RLVR (blue): Starts at ~0.30 and increases to ~0.55 with fluctuations.
* **SOKOBAN:**
* ERL: Post-refl. (light green): Starts at ~0.00, increases rapidly to ~0.70 around step 100, then fluctuates around ~0.70-0.80.
* ERL: Pre-refl. (green): Starts at ~0.00, increases rapidly to ~0.60 around step 100, then fluctuates around ~0.60-0.70.
* RLVR (blue): Remains relatively flat around ~0.00 for the entire training period.
**Bottom Row (Olmo-3-7B-Instruct):**
* **FROZENLAKE:**
* ERL: Post-refl. (light green): Starts at ~0.32 and increases to ~0.44 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.30 and increases to ~0.48 with fluctuations.
* RLVR (blue): Starts at ~0.16 and increases to ~0.36 with fluctuations.
* **HOTPOTQA:**
* ERL: Post-refl. (light green): Starts at ~0.45 and increases to ~0.60 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.40 and increases to ~0.55 with fluctuations.
* RLVR (blue): Starts at ~0.30 and increases to ~0.50 with fluctuations.
* **SOKOBAN:**
* ERL: Post-refl. (light green): Starts at ~0.02 and increases to ~0.14 with fluctuations.
* ERL: Pre-refl. (green): Starts at ~0.02 and increases to ~0.08 with fluctuations.
* RLVR (blue): Remains relatively flat around ~0.02 for the entire training period.
### Key Observations
* ERL models (both Post-refl and Pre-refl) generally outperform RLVR in all environments and with both base models (Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct).
* The FROZENLAKE environment shows the most significant performance difference between ERL and RLVR, especially with the Qwen3-4B-Instruct-2507 model.
* The SOKOBAN environment shows a delayed but significant increase in reward for ERL models, while RLVR remains consistently low.
* The Olmo-3-7B-Instruct model generally achieves lower rewards compared to the Qwen3-4B-Instruct-2507 model across all environments and algorithms.
* The "Post-refl" version of ERL generally performs slightly better than the "Pre-refl" version, although the difference is not always substantial.
### Interpretation
The data suggests that the ERL models, both with pre-reflection and post-reflection mechanisms, are more effective in learning and achieving higher rewards compared to the RLVR model across the tested environments. The FROZENLAKE environment appears to be particularly challenging for the RLVR model. The delayed performance increase in SOKOBAN for ERL models indicates a potential learning curve or a requirement for more exploration in that specific environment. The difference in performance between the Qwen3-4B-Instruct-2507 and Olmo-3-7B-Instruct models highlights the impact of the base model architecture on the overall learning outcome. The slight advantage of "Post-refl" ERL over "Pre-refl" ERL suggests that the post-reflection mechanism might contribute to more efficient or effective learning.