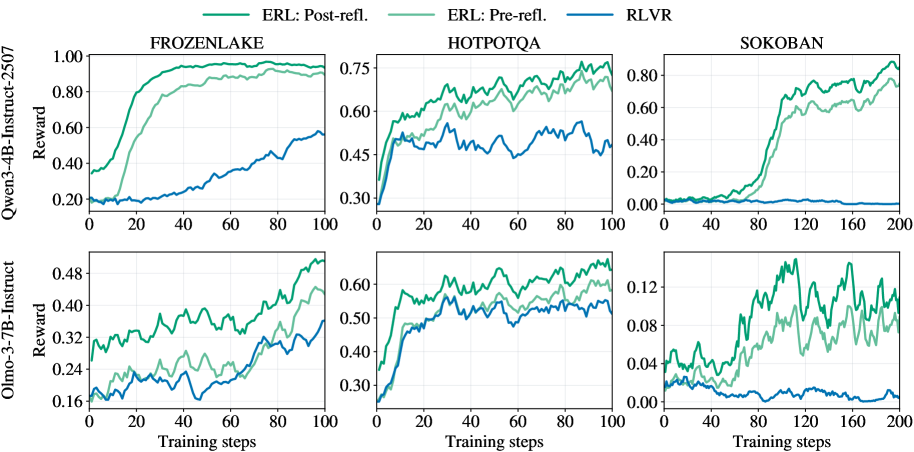
## Line Graphs: Reinforcement Learning Method Performance Comparison
### Overview
The image contains six line graphs comparing the performance of three reinforcement learning (RL) methods—ERL: Post-reflection, ERL: Pre-reflection, and RLVR—across three environments (FROZENLAKE, HOTPOTQA, SOKOBAN) at two training step milestones (100 and 200 steps). Reward values are plotted on the y-axis against training steps on the x-axis.
---
### Components/Axes
- **X-axis**: "Training steps" (ranges: 0–100 for top row, 0–200 for bottom row).
- **Y-axis**: "Reward" (scales vary by environment: 0–1.0 for FROZENLAKE/HOTPOTQA, 0–0.12 for SOKOBAN).
- **Legends**:
- Green: ERL: Post-reflection
- Light green: ERL: Pre-reflection
- Blue: RLVR
- **Graph Titles**: Environment names (FROZENLAKE, HOTPOTQA, SOKOBAN) with training step counts (100 or 200).
---
### Detailed Analysis
#### FROZENLAKE (100 steps)
- **ERL: Post-reflection** (green): Starts at ~0.2, rises sharply to ~0.9 by 100 steps.
- **ERL: Pre-reflection** (light green): Begins at ~0.1, increases gradually to ~0.7.
- **RLVR** (blue): Starts at ~0.1, climbs to ~0.45.
#### FROZENLAKE (200 steps)
- **ERL: Post-reflection**: Reaches ~0.95, plateauing near 1.0.
- **ERL: Pre-reflection**: Peaks at ~0.7, with minor fluctuations.
- **RLVR**: Stabilizes at ~0.5.
#### HOTPOTQA (100 steps)
- **ERL: Post-reflection**: Starts at ~0.3, rises to ~0.7 with minor dips.
- **ERL: Pre-reflection**: Begins at ~0.2, increases to ~0.6.
- **RLVR**: Starts at ~0.1, climbs to ~0.4.
#### HOTPOTQA (200 steps)
- **ERL: Post-reflection**: Peaks at ~0.75, with oscillations.
- **ERL: Pre-reflection**: Reaches ~0.6, with volatility.
- **RLVR**: Stabilizes at ~0.35.
#### SOKOBAN (100 steps)
- **ERL: Post-reflection**: Starts at ~0.05, rises to ~0.8 with fluctuations.
- **ERL: Pre-reflection**: Begins at ~0.02, increases to ~0.6.
- **RLVR**: Starts at ~0.0, climbs to ~0.2.
#### SOKOBAN (200 steps)
- **ERL: Post-reflection**: Peaks at ~0.9, with minor dips.
- **ERL: Pre-reflection**: Reaches ~0.7, with volatility.
- **RLVR**: Stabilizes at ~0.1.
---
### Key Observations
1. **ERL: Post-reflection** consistently outperforms other methods across all environments and training steps.
2. **ERL: Pre-reflection** performs better than RLVR but lags behind post-reflection.
3. **RLVR** shows the lowest performance, with slower convergence and lower reward ceilings.
4. **SOKOBAN** exhibits higher volatility in rewards, especially for ERL: Pre-reflection at 200 steps.
5. **FROZENLAKE** demonstrates the most stable and highest reward values for ERL: Post-reflection.
---
### Interpretation
The data suggests that **post-reflection in ERL** significantly enhances learning efficiency, likely due to iterative improvements from past experiences. Pre-reflection provides moderate gains but lacks the adaptive feedback loop of post-reflection. RLVR’s inferior performance may stem from its inability to incorporate reflection mechanisms.
Notably, **SOKOBAN’s complexity** (higher training steps and lower reward scales) amplifies the performance gap between methods, highlighting the importance of reflection in complex environments. The dip in ERL: Pre-reflection during HOTPOTQA (200 steps) could indicate overfitting or instability in early training phases. Overall, reflection-based methods (ERL) outperform non-reflective approaches (RLVR), emphasizing the value of meta-cognitive strategies in RL.