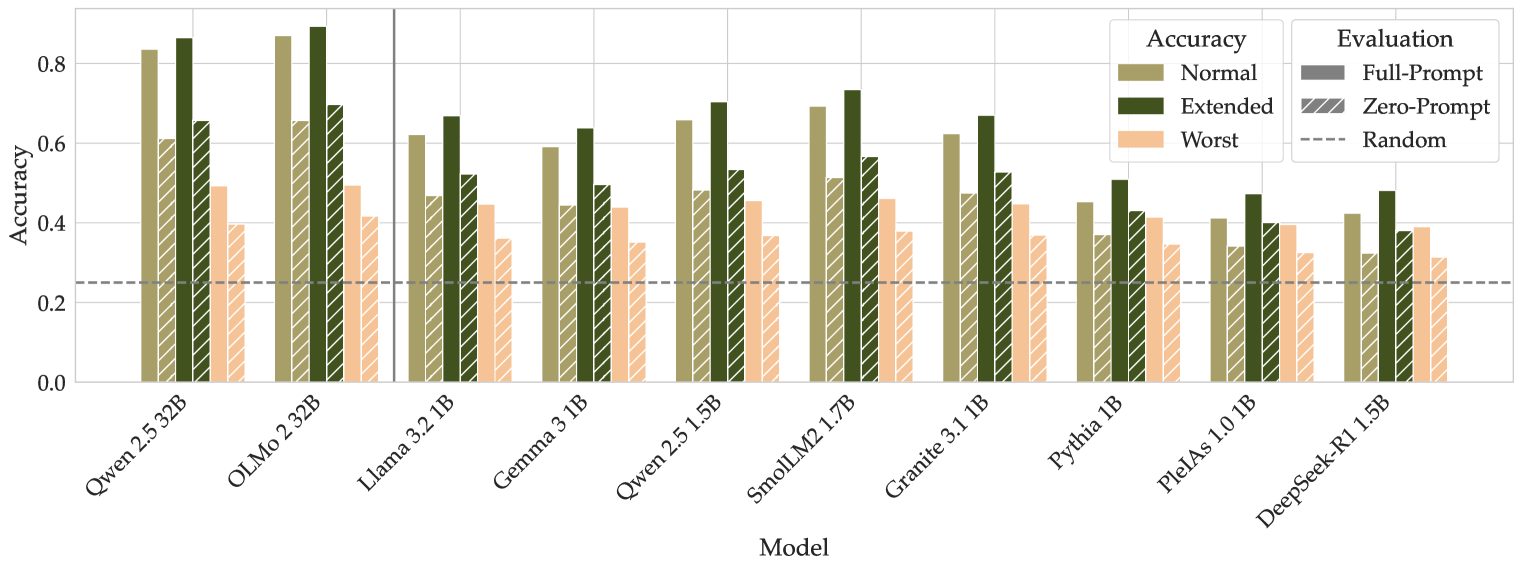
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models under various evaluation conditions. The x-axis represents the models, and the y-axis represents the accuracy score, ranging from 0.0 to 0.8. The chart includes a legend that distinguishes between different accuracy settings (Normal, Extended, Worst) and evaluation prompts (Full-Prompt, Zero-Prompt, Random).
### Components/Axes
* **X-axis:** Model names: Qwen 2.5 32B, OLMo 2 32B, Llama 3.2 1B, Gemma 3 1B, Qwen 2.5 1.5B, SmolLM2 1.7B, Granite 3.1 1B, Pythia 1B, PlelAs 1.0 1B, DeepSeek-R1 1.5B
* **Y-axis:** Accuracy, ranging from 0.0 to 0.8 in increments of 0.2.
* **Legend (Top-Right):**
* **Accuracy:**
* Normal (khaki color)
* Extended (dark olive green color)
* Worst (light peach color)
* **Evaluation:**
* Full-Prompt (gray color)
* Zero-Prompt (diagonal lines)
* Random (dashed line)
### Detailed Analysis
The chart presents accuracy scores for each model under three different accuracy settings (Normal, Extended, Worst) and two evaluation prompts (Full-Prompt, Zero-Prompt). A horizontal dashed line indicates the "Random" baseline.
Here's a breakdown of the data for each model:
* **Qwen 2.5 32B:**
* Normal: ~0.83
* Extended: ~0.66
* Worst: ~0.42
* Full-Prompt: ~0.60
* Zero-Prompt: ~0.25
* **OLMo 2 32B:**
* Normal: ~0.84
* Extended: ~0.87
* Worst: ~0.52
* Full-Prompt: ~0.69
* Zero-Prompt: ~0.25
* **Llama 3.2 1B:**
* Normal: ~0.63
* Extended: ~0.67
* Worst: ~0.44
* Full-Prompt: ~0.53
* Zero-Prompt: ~0.44
* **Gemma 3 1B:**
* Normal: ~0.59
* Extended: ~0.63
* Worst: ~0.44
* Full-Prompt: ~0.51
* Zero-Prompt: ~0.44
* **Qwen 2.5 1.5B:**
* Normal: ~0.64
* Extended: ~0.71
* Worst: ~0.44
* Full-Prompt: ~0.53
* Zero-Prompt: ~0.44
* **SmolLM2 1.7B:**
* Normal: ~0.70
* Extended: ~0.76
* Worst: ~0.45
* Full-Prompt: ~0.58
* Zero-Prompt: ~0.45
* **Granite 3.1 1B:**
* Normal: ~0.67
* Extended: ~0.68
* Worst: ~0.44
* Full-Prompt: ~0.54
* Zero-Prompt: ~0.44
* **Pythia 1B:**
* Normal: ~0.52
* Extended: ~0.55
* Worst: ~0.35
* Full-Prompt: ~0.43
* Zero-Prompt: ~0.35
* **PlelAs 1.0 1B:**
* Normal: ~0.42
* Extended: ~0.42
* Worst: ~0.32
* Full-Prompt: ~0.41
* Zero-Prompt: ~0.32
* **DeepSeek-R1 1.5B:**
* Normal: ~0.49
* Extended: ~0.40
* Worst: ~0.26
* Full-Prompt: ~0.33
* Zero-Prompt: ~0.26
### Key Observations
* The "Extended" accuracy setting generally yields the highest accuracy scores for most models.
* The "Worst" accuracy setting consistently results in the lowest accuracy scores.
* Qwen 2.5 32B and OLMo 2 32B models show the highest overall accuracy.
* PlelAs 1.0 1B and DeepSeek-R1 1.5B models show the lowest overall accuracy.
* The "Random" baseline is approximately at 0.25 accuracy.
### Interpretation
The chart provides a comparative analysis of the performance of different language models under varying conditions. The "Normal" and "Extended" accuracy settings likely represent different training or fine-tuning strategies, with "Extended" generally leading to better performance. The "Worst" setting likely represents a scenario where the model is intentionally challenged or exposed to adverse conditions.
The "Full-Prompt" and "Zero-Prompt" evaluations likely refer to different prompting strategies used during evaluation. "Full-Prompt" may involve providing the model with more context or guidance, while "Zero-Prompt" may involve evaluating the model's ability to generate responses without any specific prompts.
The "Random" baseline serves as a reference point, indicating the expected accuracy if the model were simply generating random outputs. Models with accuracy scores significantly above the "Random" baseline demonstrate a degree of learning and generalization.
The differences in performance between models highlight the impact of model architecture, training data, and evaluation strategies on overall accuracy.