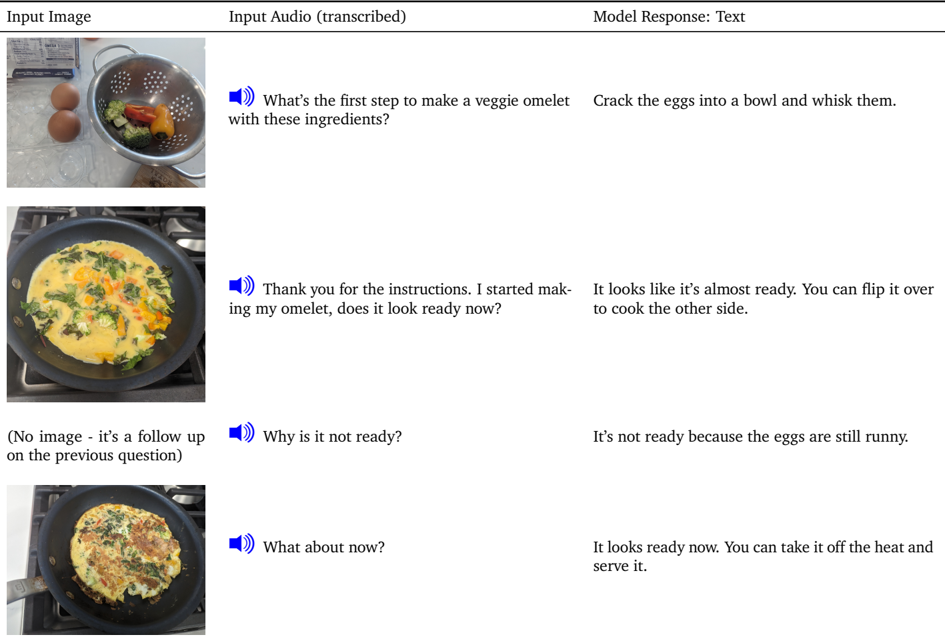
## Audio-Visual Instructional Dialogue
### Overview
The image displays a series of audio-visual instructions for making a veggie omelet. The audio is transcribed and the model's responses are provided in text format.
### Components/Axes
- **Input Image**: Shows a bowl with vegetables and eggs, a pan with a cooked omelet, and a follow-up image of a pan with a cooked omelet.
- **Input Audio (transcribed)**: Contains questions and instructions related to making a veggie omelet.
- **Model Response: Text**: Provides the text-based responses to the audio questions.
### Detailed Analysis or ### Content Details
- **First Image**: The bowl contains vegetables such as broccoli and bell peppers, and eggs. The eggs are cracked and whisked together.
- **Second Image**: The pan shows a cooked omelet with vegetables and eggs.
- **Third Image**: The pan shows a cooked omelet with vegetables and eggs, but the eggs are still runny.
- **Fourth Image**: The pan shows a cooked omelet with vegetables and eggs, and it looks ready to serve.
### Key Observations
- The model correctly identifies the first step as cracking the eggs into a bowl and whisking them.
- The model provides accurate instructions for cooking the omelet, including flipping it over to cook the other side.
- The model correctly identifies the omelet as ready to serve in the fourth image.
### Interpretation
The data suggests that the model is capable of understanding and following audio-visual instructions for making a veggie omelet. The model correctly identifies the first step and provides accurate instructions for cooking the omelet. The model also correctly identifies the omelet as ready to serve. The data demonstrates the model's ability to process and interpret audio-visual information to provide accurate responses.