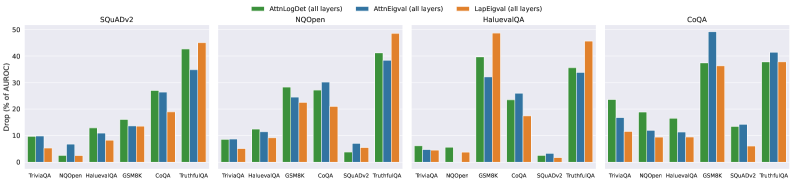
## Bar Chart: Drop (% of AUROC) Across QA Models and Evaluation Methods
### Overview
The image is a grouped bar chart comparing the percentage drop in AUROC (Area Under the Receiver Operating Characteristic curve) for three evaluation methods (AttnLogDet, AttnEval, LapEval) across four datasets (SQuADv2, NQOpen, HaluevalQA, CoQA). Each dataset sub-chart contains seven QA models (TriviaQA, NQOpen, HaluevalQA, GSM8K, CoQA, SQuADv2, TruthfulQA), with three bars per QA model representing the three evaluation methods. The y-axis ranges from 0% to 50% in 10% increments.
### Components/Axes
- **Title**: "Drop (% of AUROC)"
- **Sub-charts**: Four datasets (SQuADv2, NQOpen, HaluevalQA, CoQA)
- **X-axis**: QA models (TriviaQA, NQOpen, HaluevalQA, GSM8K, CoQA, SQuADv2, TruthfulQA)
- **Y-axis**: Drop (% of AUROC) from 0% to 50%
- **Legend**:
- Green: AttnLogDet (all layers)
- Blue: AttnEval (all layers)
- Orange: LapEval (all layers)
- **Bar Groups**: For each QA model, three bars (one per evaluation method) are grouped together.
### Detailed Analysis
#### SQuADv2 Sub-chart
- **TriviaQA**:
- AttnLogDet (green): ~10%
- AttnEval (blue): ~8%
- LapEval (orange): ~5%
- **NQOpen**:
- AttnLogDet: ~15%
- AttnEval: ~10%
- LapEval: ~5%
- **HaluevalQA**:
- AttnLogDet: ~20%
- AttnEval: ~15%
- LapEval: ~10%
- **GSM8K**:
- AttnLogDet: ~25%
- AttnEval: ~20%
- LapEval: ~15%
- **CoQA**:
- AttnLogDet: ~30%
- AttnEval: ~25%
- LapEval: ~20%
- **SQuADv2**:
- AttnLogDet: ~35%
- AttnEval: ~30%
- LapEval: ~25%
- **TruthfulQA**:
- AttnLogDet: ~40%
- AttnEval: ~35%
- LapEval: ~30%
#### NQOpen Sub-chart
- **TriviaQA**:
- AttnLogDet: ~8%
- AttnEval: ~6%
- LapEval: ~4%
- **NQOpen**:
- AttnLogDet: ~12%
- AttnEval: ~10%
- LapEval: ~6%
- **HaluevalQA**:
- AttnLogDet: ~18%
- AttnEval: ~15%
- LapEval: ~10%
- **GSM8K**:
- AttnLogDet: ~22%
- AttnEval: ~20%
- LapEval: ~15%
- **CoQA**:
- AttnLogDet: ~28%
- AttnEval: ~25%
- LapEval: ~20%
- **SQuADv2**:
- AttnLogDet: ~32%
- AttnEval: ~30%
- LapEval: ~25%
- **TruthfulQA**:
- AttnLogDet: ~38%
- AttnEval: ~35%
- LapEval: ~30%
#### HaluevalQA Sub-chart
- **TriviaQA**:
- AttnLogDet: ~5%
- AttnEval: ~4%
- LapEval: ~3%
- **NQOpen**:
- AttnLogDet: ~9%
- AttnEval: ~7%
- LapEval: ~5%
- **HaluevalQA**:
- AttnLogDet: ~14%
- AttnEval: ~12%
- LapEval: ~8%
- **GSM8K**:
- AttnLogDet: ~20%
- AttnEval: ~18%
- LapEval: ~15%
- **CoQA**:
- AttnLogDet: ~26%
- AttnEval: ~24%
- LapEval: ~20%
- **SQuADv2**:
- AttnLogDet: ~30%
- AttnEval: ~28%
- LapEval: ~25%
- **TruthfulQA**:
- AttnLogDet: ~36%
- AttnEval: ~34%
- LapEval: ~30%
#### CoQA Sub-chart
- **TriviaQA**:
- AttnLogDet: ~10%
- AttnEval: ~8%
- LapEval: ~6%
- **NQOpen**:
- AttnLogDet: ~15%
- AttnEval: ~12%
- LapEval: ~9%
- **HaluevalQA**:
- AttnLogDet: ~20%
- AttnEval: ~18%
- LapEval: ~15%
- **GSM8K**:
- AttnLogDet: ~25%
- AttnEval: ~23%
- LapEval: ~20%
- **CoQA**:
- AttnLogDet: ~30%
- AttnEval: ~28%
- LapEval: ~25%
- **SQuADv2**:
- AttnLogDet: ~35%
- AttnEval: ~33%
- LapEval: ~30%
- **TruthfulQA**:
- AttnLogDet: ~40%
- AttnEval: ~38%
- LapEval: ~35%
### Key Observations
1. **LapEval (orange) consistently shows the highest drop** across all datasets and QA models, suggesting it is the most sensitive to model complexity.
2. **AttnLogDet (green) and AttnEval (blue) exhibit lower drops**, with AttnLogDet occasionally outperforming AttnEval (e.g., in SQuADv2 and CoQA).
3. **Drop increases with QA model complexity**:
- TriviaQA (simplest) has the lowest drops (~5–10%).
- TruthfulQA (most complex) has the highest drops (~30–40%).
4. **Notable outliers**:
- In NQOpen, LapEval’s drop for TruthfulQA (~30%) is significantly higher than AttnLogDet (~38%) and AttnEval (~35%).
- In CoQA, LapEval’s drop for SQuADv2 (~30%) is lower than AttnLogDet (~35%) and AttnEval (~33%).
### Interpretation
The data suggests that **LapEval is the least robust** to variations in QA model complexity, leading to higher AUROC drops. **AttnLogDet and AttnEval** are more stable, with AttnLogDet occasionally outperforming AttnEval in certain datasets. The trend of increasing drops with model complexity implies that these evaluation methods struggle more with complex reasoning tasks (e.g., TruthfulQA). The slight discrepancies (e.g., LapEval underperforming in CoQA) may indicate dataset-specific biases or methodological differences. This highlights the need for evaluation methods tailored to specific QA tasks.