## Line Chart: Model Accuracy Comparison
### Overview
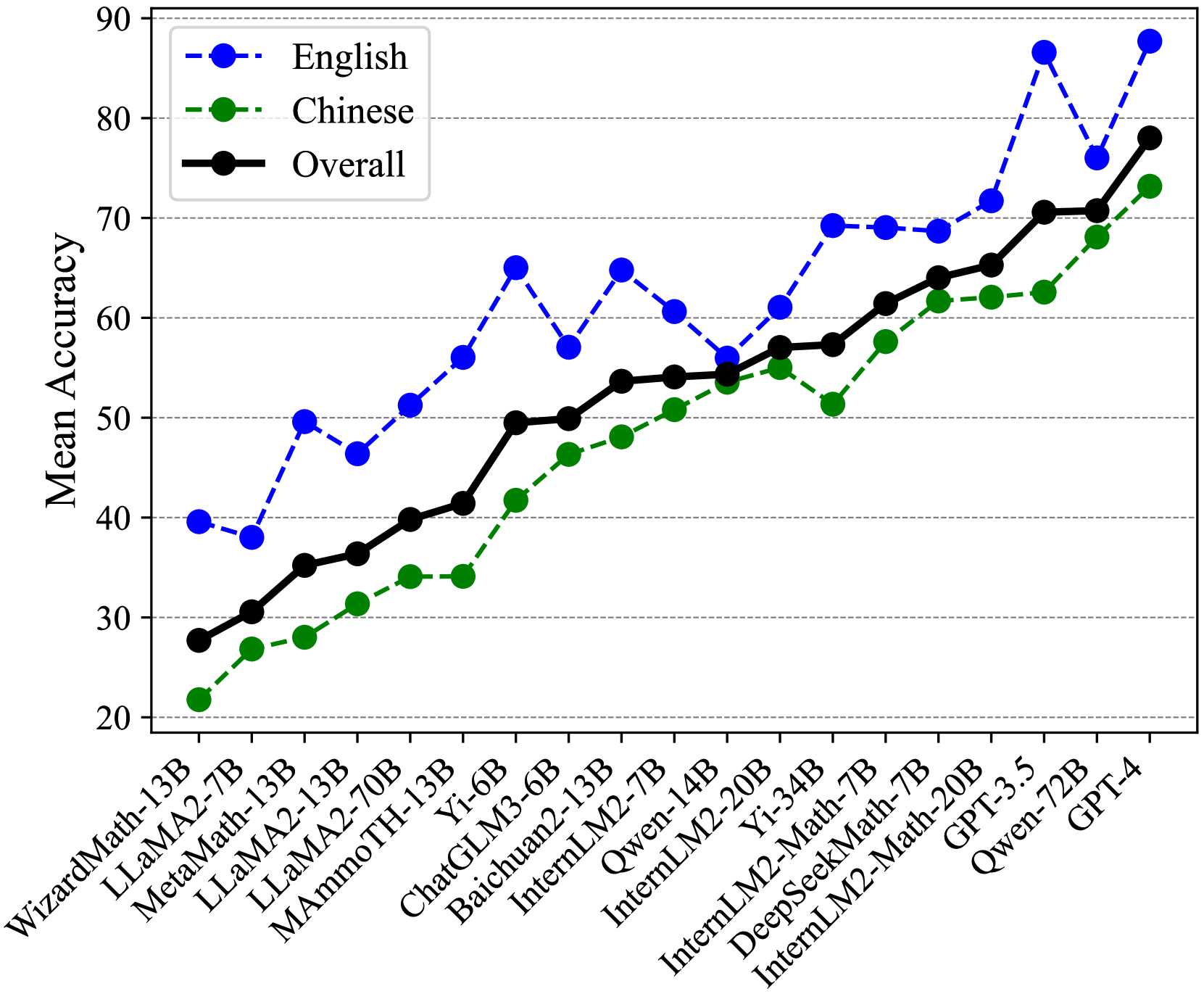
The image is a line chart comparing the mean accuracy of various language models on English and Chinese datasets, as well as their overall performance. The x-axis represents different language models, and the y-axis represents the mean accuracy, ranging from 20 to 90. The chart includes three data series: English (blue dashed line), Chinese (green dashed line), and Overall (black solid line).
### Components/Axes
* **Title:** None
* **X-axis:** Language Models (WizardMath-13B, LLaMA2-7B, MetaMath-13B, LLaMA2-13B, LLaMA2-70B, MAmmoTH-13B, Yi-6B, ChatGLM3-6B, Baichuan2-13B, InternLM2-7B, Qwen-14B, InternLM2-20B, Yi-34B, InternLM2-Math-7B, DeepSeekMath-7B, InternLM2-Math-20B, GPT-3.5, Qwen-72B, GPT-4)
* **Y-axis:** Mean Accuracy, ranging from 20 to 90 in increments of 10.
* **Legend:** Located in the top-left corner.
* English: Blue dashed line with circular markers
* Chinese: Green dashed line with circular markers
* Overall: Black solid line with circular markers
### Detailed Analysis
**English (Blue Dashed Line):**
The English accuracy fluctuates more than the other two lines.
* WizardMath-13B: ~40
* LLaMA2-7B: ~38
* MetaMath-13B: ~50
* LLaMA2-13B: ~47
* LLaMA2-70B: ~65
* MAmmoTH-13B: ~57
* Yi-6B: ~65
* ChatGLM3-6B: Not Available
* Baichuan2-13B: Not Available
* InternLM2-7B: ~62
* Qwen-14B: ~69
* InternLM2-20B: ~69
* Yi-34B: ~70
* InternLM2-Math-7B: Not Available
* DeepSeekMath-7B: Not Available
* InternLM2-Math-20B: ~88
* GPT-3.5: ~75
* Qwen-72B: ~89
* GPT-4: Not Available
**Chinese (Green Dashed Line):**
The Chinese accuracy generally increases across the models.
* WizardMath-13B: ~22
* LLaMA2-7B: ~27
* MetaMath-13B: ~32
* LLaMA2-13B: ~34
* LLaMA2-70B: ~42
* MAmmoTH-13B: ~48
* Yi-6B: ~48
* ChatGLM3-6B: Not Available
* Baichuan2-13B: Not Available
* InternLM2-7B: ~54
* Qwen-14B: ~52
* InternLM2-20B: ~52
* Yi-34B: ~58
* InternLM2-Math-7B: Not Available
* DeepSeekMath-7B: Not Available
* InternLM2-Math-20B: ~62
* GPT-3.5: ~67
* Qwen-72B: ~70
* GPT-4: ~73
**Overall (Black Solid Line):**
The overall accuracy shows a general upward trend.
* WizardMath-13B: ~28
* LLaMA2-7B: ~31
* MetaMath-13B: ~36
* LLaMA2-13B: ~40
* LLaMA2-70B: ~50
* MAmmoTH-13B: ~50
* Yi-6B: ~54
* ChatGLM3-6B: Not Available
* Baichuan2-13B: Not Available
* InternLM2-7B: ~54
* Qwen-14B: ~57
* InternLM2-20B: ~64
* Yi-34B: ~60
* InternLM2-Math-7B: Not Available
* DeepSeekMath-7B: Not Available
* InternLM2-Math-20B: ~71
* GPT-3.5: ~71
* Qwen-72B: ~71
* GPT-4: ~78
### Key Observations
* The English accuracy fluctuates more significantly than the Chinese and Overall accuracies.
* The Overall accuracy generally increases as the models progress along the x-axis.
* The Chinese accuracy consistently lags behind the English accuracy for most models.
* The models on the right side of the chart (GPT-3.5, Qwen-72B, GPT-4) generally exhibit higher accuracy across all three metrics.
### Interpretation
The chart illustrates the performance of various language models on English and Chinese datasets. The fluctuating English accuracy suggests that some models are better suited for English tasks than others, while the consistently lower Chinese accuracy indicates a potential gap in model performance across different languages. The upward trend in overall accuracy suggests that newer models generally perform better than older models. The models GPT-3.5, Qwen-72B, and GPT-4 show the highest overall performance, indicating their superior capabilities in both English and Chinese language tasks. The data suggests that model architecture and training data play a significant role in determining language-specific performance.