## Line Chart: Mean Accuracy of Language Models by Language
### Overview
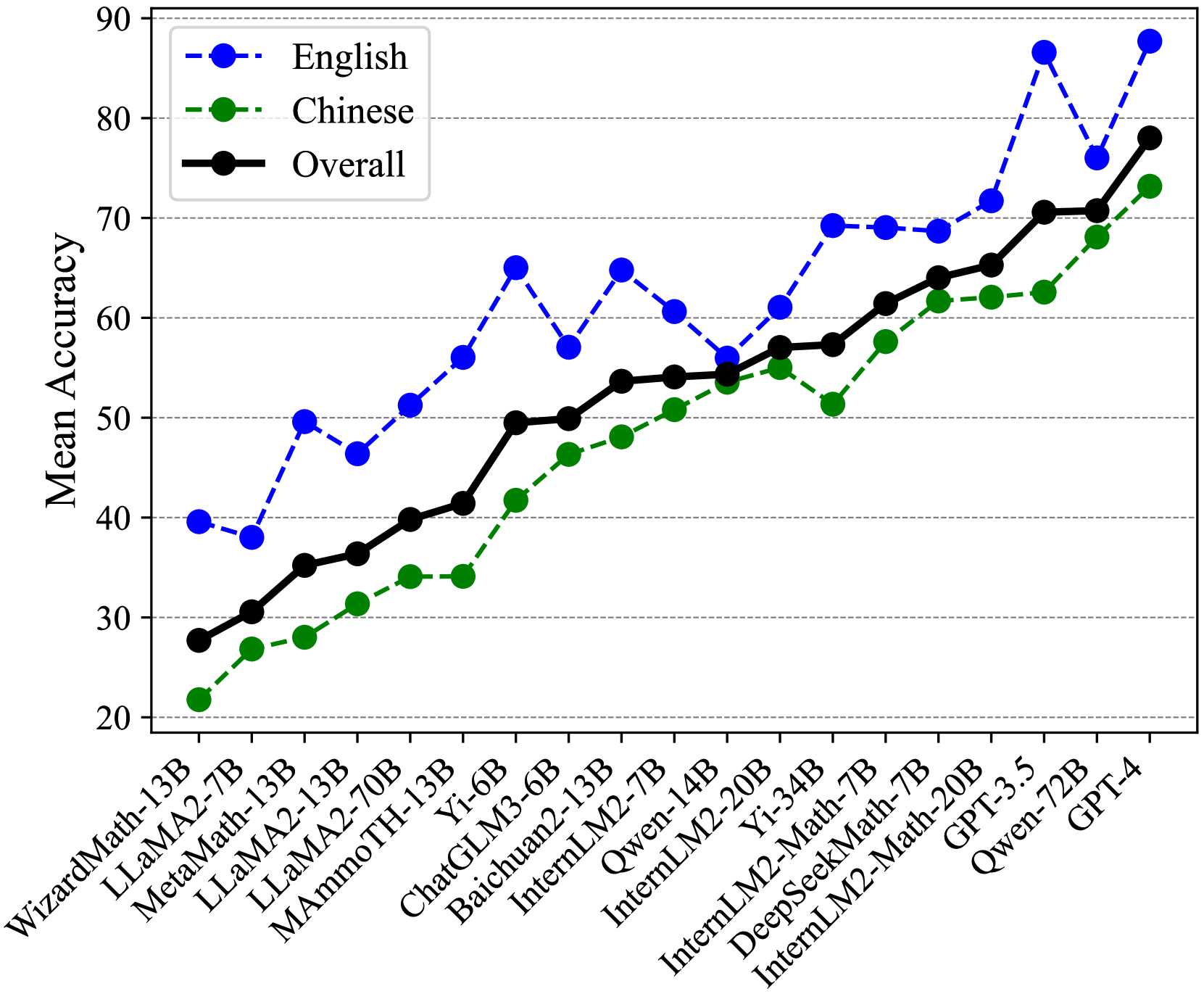
This image is a line chart comparing the mean accuracy of various large language models (LLMs) across three categories: English, Chinese, and an Overall score. The chart plots model names on the x-axis against a "Mean Accuracy" score (ranging from 20 to 90) on the y-axis. The data suggests a general upward trend in model performance from left to right, with English performance consistently outperforming Chinese performance for most models.
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **Y-Axis:**
* **Title:** "Mean Accuracy"
* **Scale:** Linear, from 20 to 90, with major gridlines at intervals of 10.
* **X-Axis:**
* **Labels (from left to right):** WizardMath-13B, LLaMA2-7B, MetaMath-13B, LLaMA2-13B, LLaMA2-70B, MAmmoTH-13B, Yi-6B, ChatGLM3-6B, Baichuan2-13B, InternLM2-7B, Qwen-14B, InternLM2-20B, Yi-34B, InternLM2-Math-7B, DeepSeekMath-7B, InternLM2-Math-20B, GPT-3.5, Qwen-72B, GPT-4.
* **Legend (Top-Left Corner):**
* **Blue dashed line with circle markers:** "English"
* **Green dashed line with circle markers:** "Chinese"
* **Black solid line with circle markers:** "Overall"
### Detailed Analysis
The following table reconstructs the approximate data points for each model, based on visual inspection of the chart. Values are estimated to the nearest integer.
| Model Name | English Accuracy (Blue) | Chinese Accuracy (Green) | Overall Accuracy (Black) |
| :--- | :--- | :--- | :--- |
| WizardMath-13B | ~40 | ~22 | ~28 |
| LLaMA2-7B | ~38 | ~27 | ~31 |
| MetaMath-13B | ~50 | ~28 | ~35 |
| LLaMA2-13B | ~47 | ~31 | ~36 |
| LLaMA2-70B | ~51 | ~34 | ~40 |
| MAmmoTH-13B | ~56 | ~34 | ~41 |
| Yi-6B | ~65 | ~42 | ~50 |
| ChatGLM3-6B | ~57 | ~46 | ~50 |
| Baichuan2-13B | ~65 | ~48 | ~54 |
| InternLM2-7B | ~61 | ~51 | ~54 |
| Qwen-14B | ~56 | ~54 | ~55 |
| InternLM2-20B | ~61 | ~55 | ~57 |
| Yi-34B | ~69 | ~51 | ~58 |
| InternLM2-Math-7B | ~69 | ~58 | ~61 |
| DeepSeekMath-7B | ~69 | ~62 | ~64 |
| InternLM2-Math-20B | ~72 | ~62 | ~65 |
| GPT-3.5 | ~86 | ~63 | ~70 |
| Qwen-72B | ~76 | ~68 | ~71 |
| GPT-4 | ~88 | ~73 | ~78 |
**Trend Verification:**
* **English (Blue Dashed Line):** Shows a general upward trend with significant volatility. Notable peaks occur at Yi-6B, Baichuan2-13B, and a very sharp increase at GPT-3.5 and GPT-4. There are dips at LLaMA2-7B, LLaMA2-13B, ChatGLM3-6B, and Qwen-14B.
* **Chinese (Green Dashed Line):** Shows a steadier, more consistent upward trend with fewer sharp fluctuations. The growth is relatively smooth from WizardMath-13B to GPT-4.
* **Overall (Black Solid Line):** Follows a smooth, consistent upward trajectory that generally lies between the English and Chinese lines, acting as an average. It shows very few dips.
### Key Observations
1. **Performance Hierarchy:** For nearly every model, the English accuracy score is higher than the Chinese score, which is in turn higher than or equal to the Overall score. The Overall line is a composite metric.
2. **Model Progression:** There is a clear, general trend of increasing accuracy from older/smaller models on the left (e.g., WizardMath-13B) to newer/larger models on the right (e.g., GPT-4).
3. **Significant Outliers:**
* **GPT-3.5** shows a dramatic spike in English accuracy (~86), far above its Chinese (~63) and Overall (~70) scores, creating the largest gap between English and Chinese performance on the chart.
* **Yi-34B** exhibits a notable dip in Chinese accuracy (~51) compared to its neighbors, while its English accuracy remains high (~69).
* **Qwen-14B** is an instance where the Chinese accuracy (~54) nearly matches the English accuracy (~56), showing one of the smallest language performance gaps.
4. **Top Performers:** GPT-4 leads in all three categories (English: ~88, Chinese: ~73, Overall: ~78). Qwen-72B and GPT-3.5 follow in the overall ranking.
### Interpretation
This chart visualizes the progression and comparative capabilities of LLMs, likely on a mathematical or reasoning benchmark given the model names (e.g., "Math"). The data demonstrates two key findings:
1. **The English Advantage:** Most models, especially Western-developed ones like GPT-3.5, show a significant performance advantage in English over Chinese. This suggests potential biases in training data or architectural optimizations favoring English-language tasks.
2. **The Closing Gap:** Newer models, particularly those from Chinese labs (e.g., Qwen-72B, InternLM2-Math-20B), show a narrowing gap between English and Chinese performance. This indicates successful efforts in improving multilingual capabilities, especially for Chinese.
3. **Overall Trend:** The consistent rise of the black "Overall" line signifies broad, across-the-board improvements in model capabilities over successive generations. The volatility in the English line suggests that gains in English performance may be less stable or more sensitive to specific model architectures and training techniques compared to the steadier improvements in Chinese performance.
The chart serves as a benchmark snapshot, highlighting both the current state-of-the-art (GPT-4) and the dynamic landscape of LLM development, where language-specific performance remains a critical differentiator.