## Line Graph: Mean Accuracy Comparison Across Language Models
### Overview
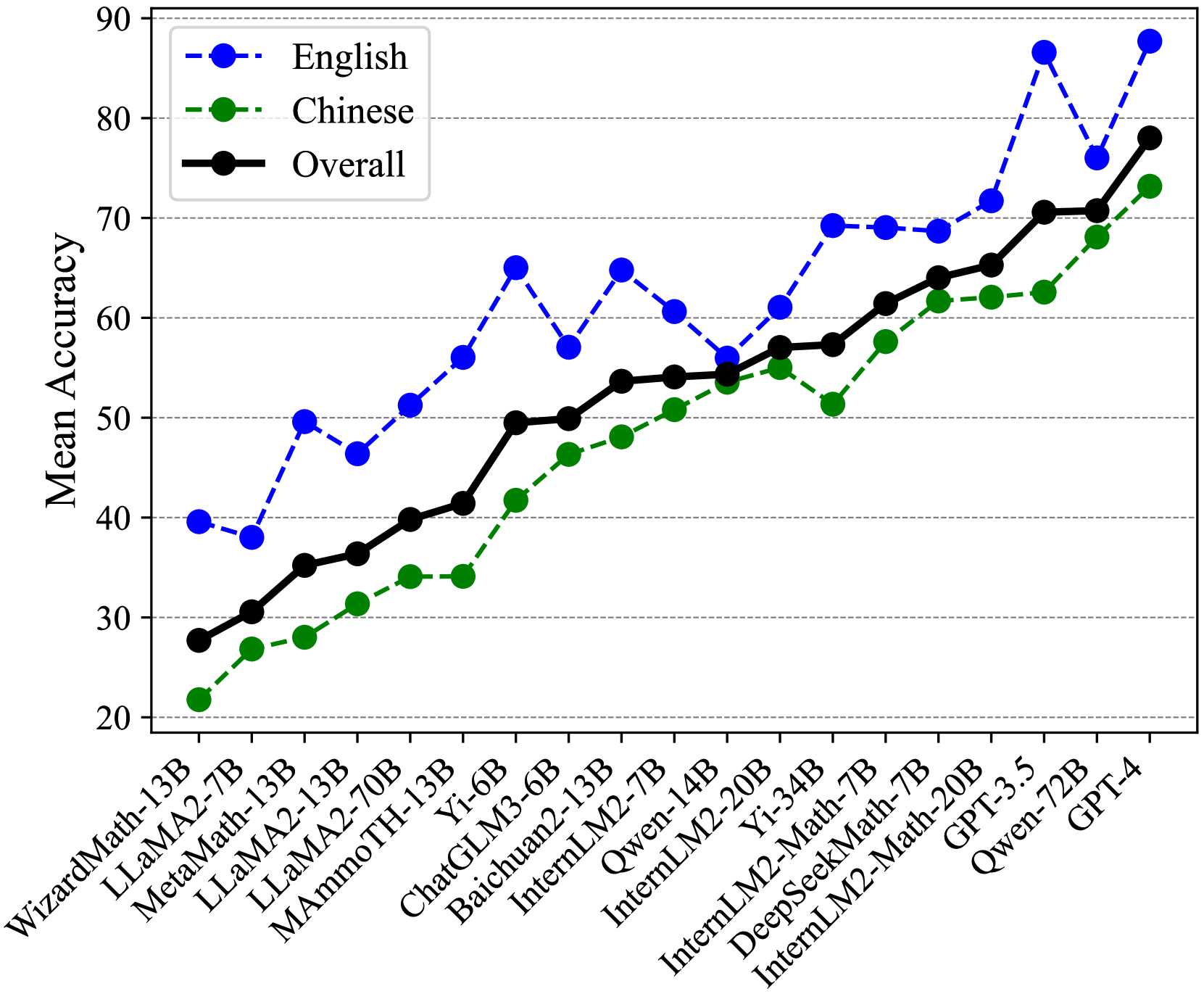
The image displays a line graph comparing mean accuracy performance across multiple language models (LMs) for English, Chinese, and overall metrics. The graph spans 20-90% accuracy on the y-axis and lists 18 models on the x-axis, ranging from WizardMath-13B to GPT-4.
### Components/Axes
- **X-axis**: Model names (e.g., WizardMath-13B, LLaMA2-7B, Yi-34B, GPT-4)
- **Y-axis**: Mean Accuracy (20-90% in 10% increments)
- **Legend**:
- Blue dashed line: English
- Green dash-dot line: Chinese
- Black solid line: Overall
- **Placement**: Legend in top-left corner; data points connected by lines with markers
### Detailed Analysis
1. **English (Blue Dashed Line)**:
- Starts at ~40% (WizardMath-13B), peaks at ~88% (GPT-4)
- Notable dip to ~55% at Yi-34B, then sharp rise to 88% at GPT-4
- Average accuracy: ~65% (excluding GPT-4 outlier)
2. **Chinese (Green Dash-Dot Line)**:
- Begins at ~22% (WizardMath-13B), rises steadily to ~73% (GPT-4)
- Sharp dip to ~51% at InternLM2-7B, then recovery to 73%
- Average accuracy: ~55% (excluding GPT-4 outlier)
3. **Overall (Black Solid Line)**:
- Starts at ~28% (WizardMath-13B), climbs to ~78% (GPT-4)
- Consistent upward trend with minor fluctuations
- Average accuracy: ~55% (excluding GPT-4 outlier)
### Key Observations
- **Performance Gaps**: English models consistently outperform Chinese models by 10-15% across most models
- **Outliers**:
- GPT-4 shows extreme performance (88% English, 73% Chinese)
- Yi-34B causes English accuracy drop to 55%
- InternLM2-7B causes Chinese accuracy drop to 51%
- **Trend Patterns**:
- English: Volatile with high peaks
- Chinese: Steady growth with mid-range dip
- Overall: Smooth progression with minor fluctuations
### Interpretation
The data suggests English language models generally achieve higher accuracy than Chinese models, with GPT-4 demonstrating exceptional performance across both languages. The dips observed in Yi-34B (English) and InternLM2-7B (Chinese) indicate potential model-specific limitations or evaluation challenges. The overall metric tracks closely with English performance, suggesting English evaluation may dominate the composite metric. The consistent gap between English and Chinese performance highlights persistent challenges in Chinese language model development compared to English counterparts.